Pandas-Introduction
What is pandas?
Pandas is a python open source library which allow you to perform data manipulation, analysis and cleaning. It is build on top of NumPy . It is a most important library for data science.
According to Wikipedia “Pandas is derived from the term “panel data”, an econometrics term for data sets that include observations over multiple time periods for the same individuals.”
Why Pandas?
Following are the advantages of pandas for Data Scientist.
- Easily handling missing data.
- It provides an efficient way to slicing and data wrangling.
- It is helpful to merge, concatenate or reshape the data.
- It has includes a powerful time series tool to work with.
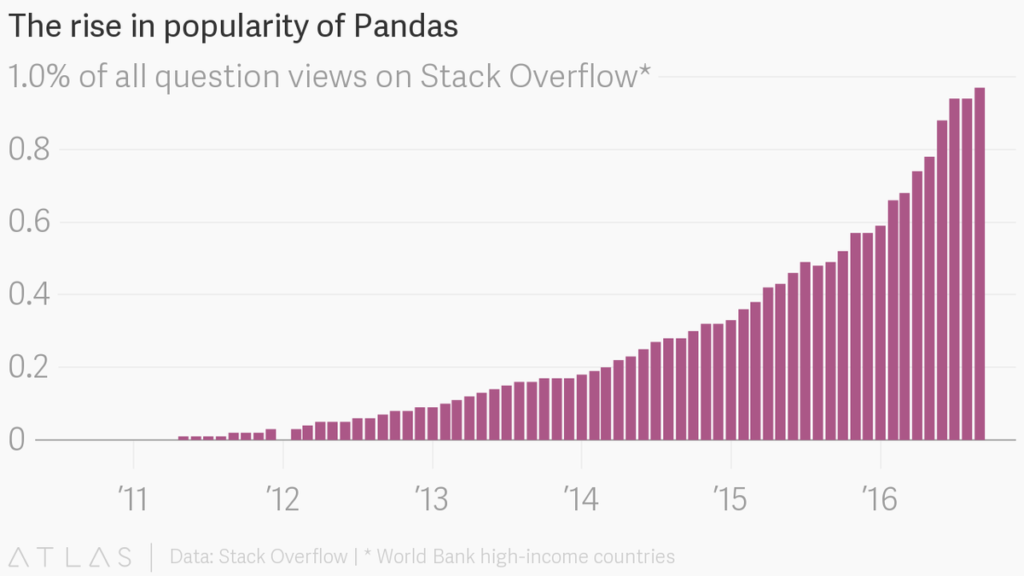
How to install Pandas?
To install python pandas go to command line/terminal and type “pip install pandas” or else if you have anaconda install in the system just type in “conda install pandas”. Once the installation is completed, go to your IDE(Jupyter) and simply import it by typing “import pandas as pd”.
In next chapter we will learn about pandas Series.
Leave a Reply