Why Python for data Analysis?
Python is very easy to learn and implement. For many people including myself python language is easy to fall in love with. Since his first appearance in 1991, python popularity is increasing day by day. Among interpreted languages Python is distinguished by its large and active scientific computing community. Adoption of Python for scientific computing in both industry applications and academic research has increased significantly since the early 2000s.
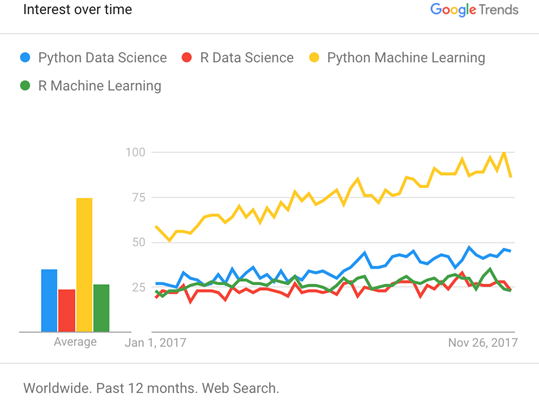
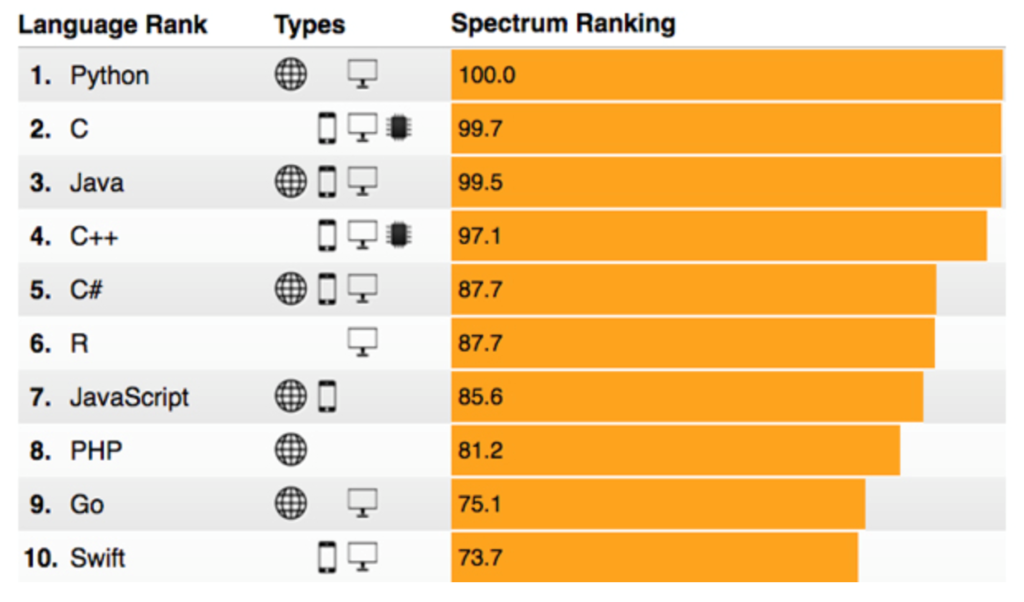
For data analysis and exploratory analysis and data visualization, Python has upper hand as compare with the many other domain-specific open source and commercial programming languages and tools, such as R, MATLAB, SAS, Stata, and others. In recent years, Python’s improved library support (primarily pandas) has made it a strong alternative for data manipulation tasks. Combined with python’s strength in general purpose programming, it is an excellent choice as a single language for building data-centric applications.
So in short we can say due to following reason we should choose python for data analysis.
- It’s very simple language to understand.
- It’s an open source.
- Strong data science inbuilt library.
- Apart from the long existing demand in the web development projects, the use of Python is only growing to grow as AI/ML projects become more main stream and popular with global businesses.
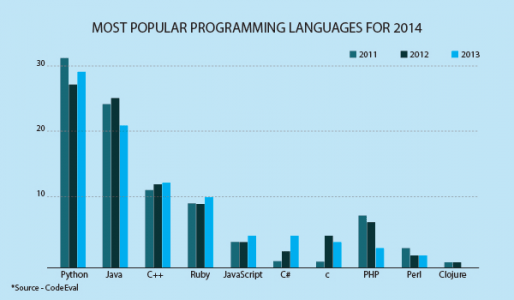
As you can see below chart, python is the most shouting language in the industry.