Classification VS Regression
Before going to start working on machine learning model, we need to understand difference between classification and regression problem. Classification and Regression are two major prediction problems which are usually dealt in Data mining.
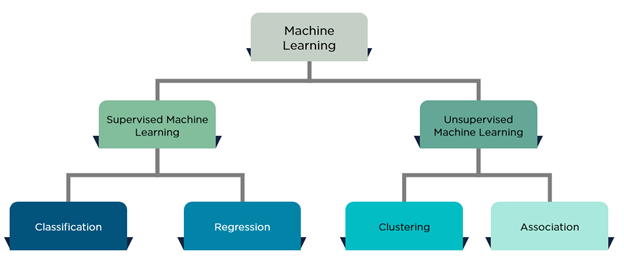
Although Classification and Regression come under the same umbrella of Supervised Machine Learning and share the common concept of using past data to make predictions, or take decisions, that’s where their similarity ends.
Regression in machine learning:
A regression problem is when the output variable is a real or continuous value, such as “salary” or “weight” or “sales”.
In machine learning, regression algorithms try to calculate the mapping function (f) from the input variables (x) to numerical or continuous output variables (y). In this case, y is a real value, which can be an integer or a floating point value. Therefore, regression prediction problems are usually quantities or sizes.
For example, when provided with a dataset about houses and you are asked to predict their prices that are a regression task because price will be a continuous output.
Common regression algorithms are: Linear regression, Support Vector Regression (SVR), and regression trees.
Note – Logistic regression, have the name “regression” in their names but they are not regression algorithms.
Classification in machine learning:
A classification problem is when the output variable is a category, such as “black” or “blue” or “disease” and “no disease”.
In classification algorithms we try to calculate the mapping function (f) from the input variables (x) to discrete or categorical output variables (y).
For example, we have a house dataset and we have to predict whether the prices for the houses “sell more or less than the recommended retail price”. Here, the houses will be classified whether their prices fall into two discrete categories: above or below the said price.
Common classification algorithms are logistic regression, Naïve Bayes, decision trees, and K Nearest Neighbours.
So following are the main differences:
| Basic for comparison | Classification | Regression |
| Definition | A classification problem is when the output variable is category such as ‘blue’ or ‘black’, disease and no disease | A regression problem is when the output variable is real or continuous value such as sales, weight, salary |
| Involve prediction of | Categorical value | Continuous value |
| Algorithm | Decision tree, logistic regression, etc | Regression tree (Random forest), Linear regression, etc. |
| Nature of the predicted data | Unordered | Ordered |
| Method of calculation | Measuring accuracy | Measurement of root mean square error |
Leave a Reply