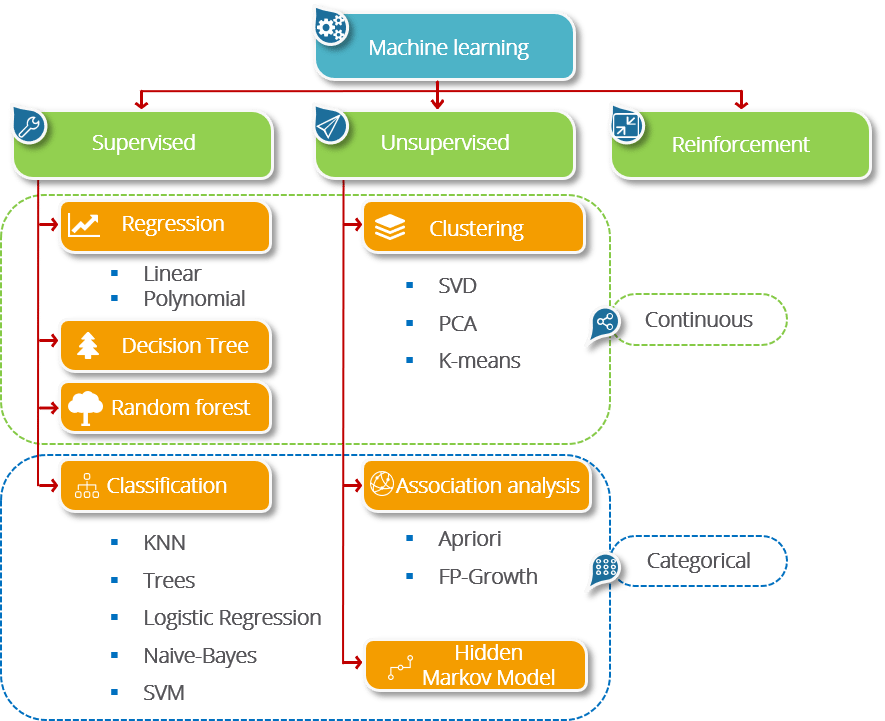
Types of Machine Learning
There are several Machine Learning algorithm and techniques which is used to build models for solving real-life problems by using data.
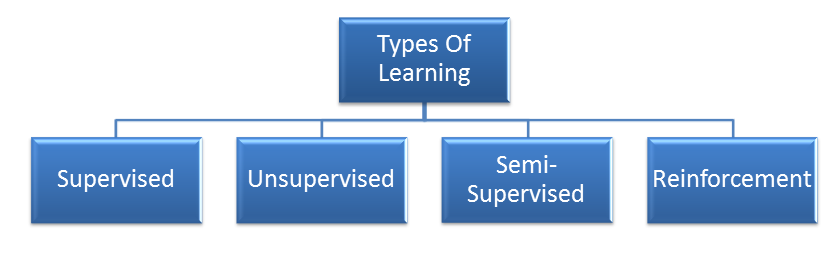
Now let’s discuss each type in details.
Supervised Learning:
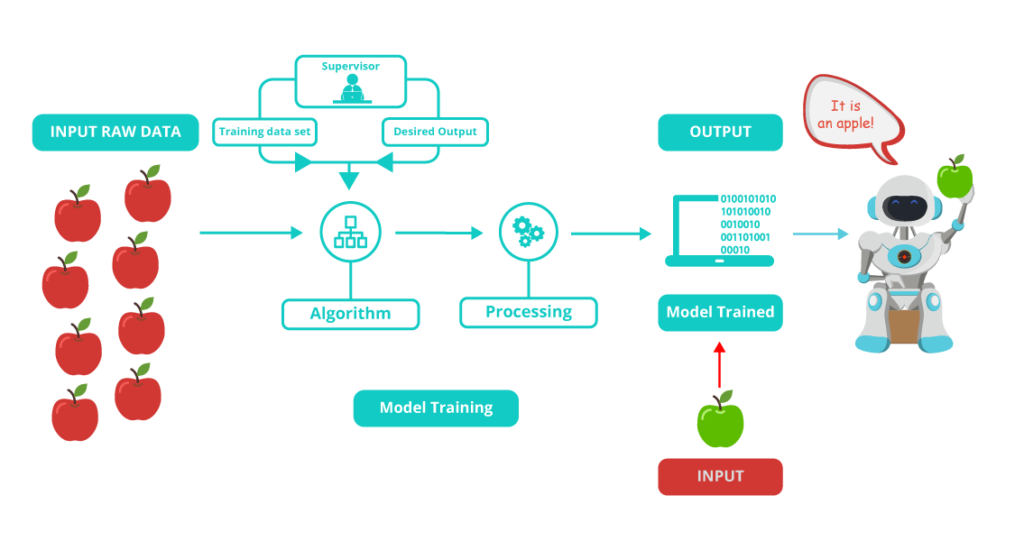
Supervised learning technique is use when data set is structured. Structured dataset is one which has both input and output parameters. It is called supervised learning because we have a dataset which acts as a teacher and its role is to train the model or the machine. Once the model gets trained it can start making a prediction or decision when new data is given to it.
Supervised learning is the one where you have input variables (x) and an output variable (Y) and you use an algorithm to learn the mapping function from the input to the output.
Y = f(X)
The goal is to approximate the mapping function so well that whenever you get new input data (x), the machine can easily predict the output variables (Y) for that data.
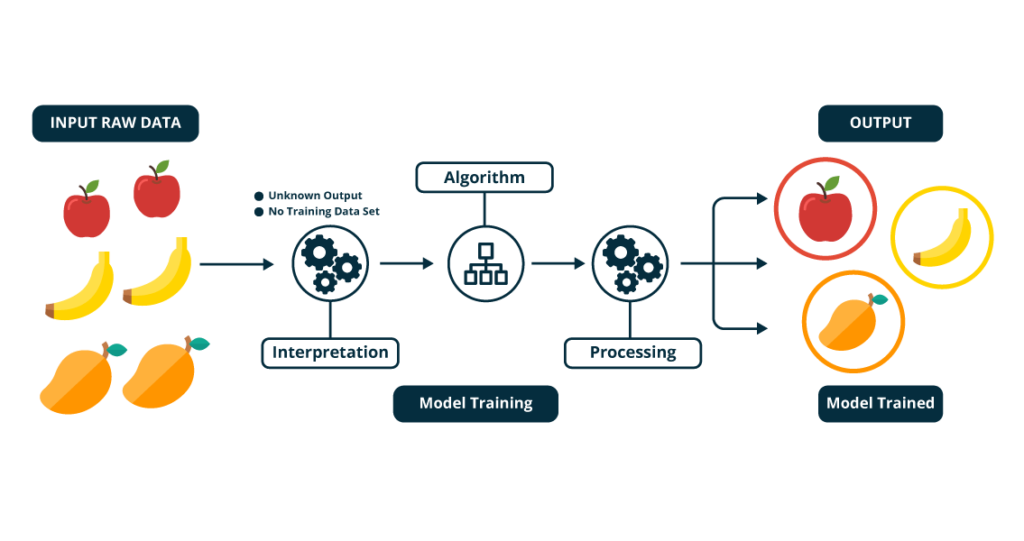
Unsupervised Learning:
Unsupervised learning is where we only have input data (X) and no corresponding output variables i.e Y.
The unsupervised model learns through observation and finds structures in the data. Once the model is given a dataset, it automatically finds patterns and relationships in the dataset by creating clusters in it. Unsupervised learning is used for raw datasets. Its main task is to convert raw data to structured data.
Now let’s understand both type of learning in details with example.

Suppose you had a basket and it is filled with some different kinds of fruits, your task is to arrange them as groups. For understanding let me clear the names of the fruits in our basket. We have four types of fruits. They are: apple, banana, grape and cherry.
SUPERVISED LEARNING:
- You already learn from your previous work about the physical characters of fruits.
- So arranging the same type of fruits at one place is easy now.
- Your previous work is called as training data in data mining.
- So, you already learn the things from your train data, this is because of response variable.
- Response variable mean just a decision variable.
You can observe response variable below (FRUIT NAME) .
| NO. | SIZE | COLOR | SHAPE | FRUIT NAME |
| 1 | Big | Red | Rounded shape with a depression at the top | Apple |
| 2 | Small | Red | Heart-shaped to nearly globular | Cherry |
| 3 | Big | Green | Long curving cylinder | Banana |
| 4 | Small | Green | Round to oval, Bunch shape Cylindrical | Grape |
- Suppose you have taken an new fruit from the basket then you will see the size, color and shape of that particular fruit.
- If size is Big, color is Red, shape is rounded shape with a depression at the top, you will conform the fruit name as apple and you will put in apple group. Likewise for other fruits also.
- Job of groping fruits was done and happy ending.
- You can observe in the table that a column was labelled as “FRUIT NAME” this is called as response variable.
- If you learn the thing before from training data and then applying that knowledge to the test data(for new fruit), This type of learning is called as Supervised Learning.
- Classification come under Supervised learning.
UNSUPERVISED LEARNING
- Suppose you had a basket and it is filled with some different types fruits,your task is to arrange them as groups.
- This time you don’t know anything about that fruits, honestly saying this is the first time you have seen them.
- So how will you arrange them? What will you do first?
- You will take a fruit and you will arrange them by considering physical character of that particular fruit. suppose you have considered color.
- Then you will arrange them on considering base condition as color.
- Then the groups will be something like this.
- RED COLOR GROUP: apples & cherry fruits.
- GREEN COLOR GROUP: bananas & grapes.
- So now you will take another physical character such as size .
- RED COLOR AND BIG SIZE: apple.
- RED COLOR AND SMALL SIZE: cherry fruits.
- GREEN COLOR AND BIG SIZE: bananas.
- GREEN COLOR AND SMALL SIZE: grapes.
- Job done happy ending.
- Here you didn’t know learn anything before, means no train data and no response variable.
- This type of learning is known as unsupervised learning.
- Clustering comes under unsupervised learning.
Semi-Supervised Learning:
As per name suggestion same supervised learning is a combination of Supervise learning and unsupervised learning and uses both labelled and unlabelled data for training. We use this type of Machine Learning for classification, regression, and prediction. Examples of semi-supervised learning are face- and voice-recognition applications.
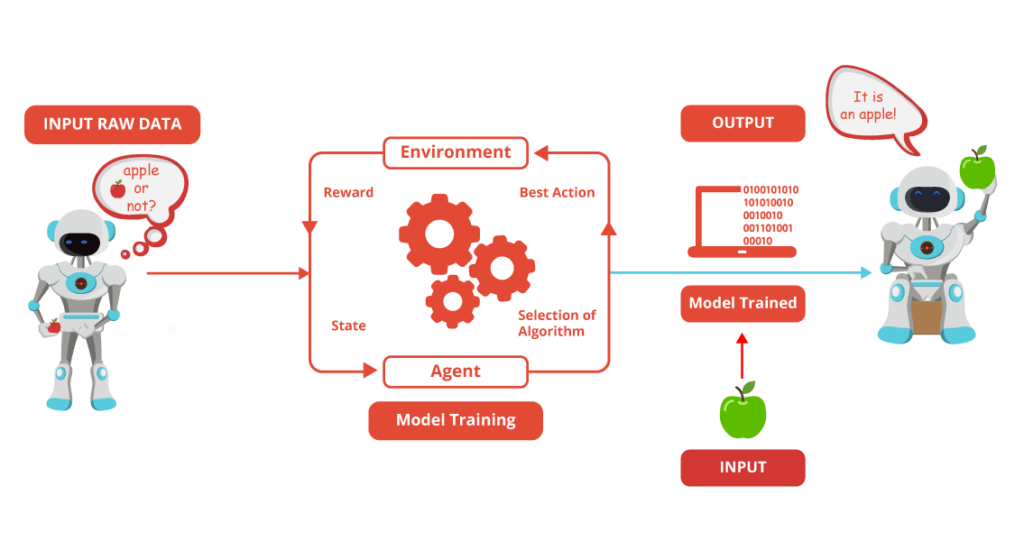
Reinforcement Learning:
It follows traditional types of data analysis where algorithm discovers data through a process of trial and error and find out what is the best outcome.
There are three main components make up reinforcement learning: the agent, the environment, and the actions. The agent is the learner or decision-maker, the environment includes everything that the agent interacts with, and the actions are what the agent does.
Following are the hierarchy of machine learning.
Leave a Reply