Pandas-DataFrame
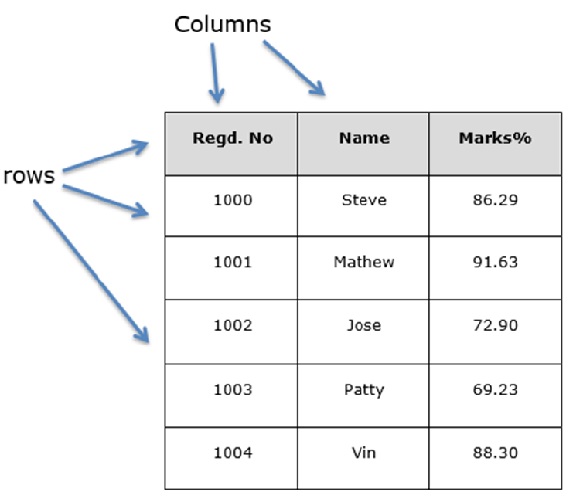
A data frame is a standard way to store data and data is aligned in a tabular fashion in rows and columns.
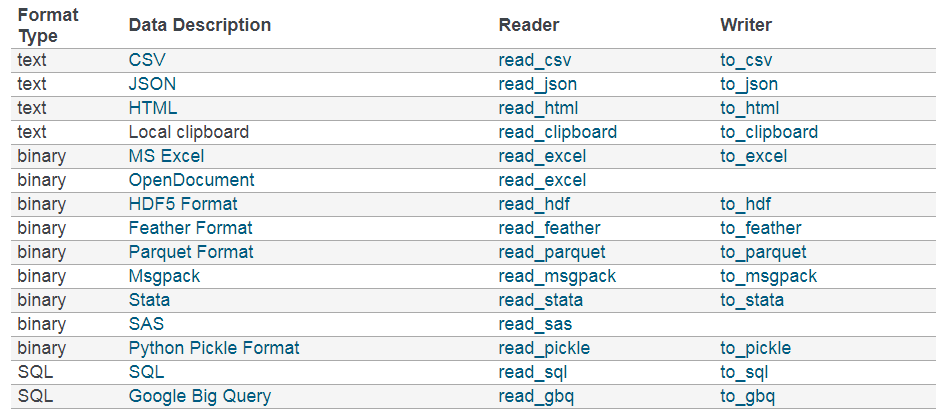
DataFrames are the workhorse of pandas and are directly inspired by the R programming language. We can think of a DataFrame as a bunch of Series objects put together to share the same index Let us assume that we are creating a data frame with student’s data, it will look something like this.
A pandas DataFrame can be created using the following constructor
pandas.DataFrame( data, index, columns, dtype, copy)
- Data – data takes various forms like ndarray, series, map, lists, dict, constants and also another DataFrame.
- Index – For the row labels, the Index to be used for the resulting frame is Optional Default np.arrange(n) if no index is passed.
- Columns – For column labels, the optional default syntax is – np.arrange(n). This is only true if no index is passed.
- dtype – Data type of each column.
- Copy – This command (or whatever it is) is used for copying of data, if the default is False.
Creations of DataFrame:
A pandas DataFrame can be created using various inputs like list, dict, series, numpy ndarray, another dataframe.
Let’s explore DataFrame with python in jupyter notebook.