Databrics interview questions and answers – 2023
1. What is Databrics ?
Databricks provides a collaborative and interactive workspace that allows data engineers, data scientists, and analysts to work together on big data projects. It supports various programming languages, including Scala, Python, R, and SQL, making it accessible to a wide range of users.
The platform’s core component is Apache Spark, which enables distributed data processing and analysis across large clusters of computers. Databricks simplifies the deployment and management of Spark clusters, abstracting away much of the underlying infrastructure complexities.
Key features of Databricks include:
Unified Analytics: Databricks offers a collaborative workspace where users can write and execute code, explore data, visualize results, and share insights with their teams.
Apache Spark Integration: Databricks integrates with Apache Spark, providing a high-level interface to manage and scale Spark clusters for big data processing.
Delta Lake: This is an additional feature offered by Databricks, providing a versioned, transactional data lake that improves data reliability and simplifies data management.
Machine Learning: Databricks supports building and deploying machine learning models using popular libraries like MLlib, Scikit-learn, and TensorFlow.
Data Integration: Databricks can connect to various data sources, such as data lakes, databases, and data warehouses, allowing users to analyze and process data from multiple sources.
Job Scheduling: Users can schedule and automate data processing jobs, making it easier to run repetitive tasks at specific times or intervals.
Security and Collaboration: Databricks provides role-based access control and allows teams to collaborate securely on projects.
2. What is the difference between Databrics and Data factory?
In simple terms, Databricks is a platform for big data analysis and machine learning, while Data Factory is a cloud-based service used for data integration, movement, and orchestration. Databricks is more suitable for data analysis and advanced analytics tasks, while Data Factory is ideal for data movement and transformation between different data sources and destinations.
| Aspect | Databricks | Data Factory |
| Purpose | Unified data analytics platform | Cloud-based data integration and orchestration service |
| Function | Analyzing and processing big data | Moving, transforming, and orchestrating data between various sources and destinations |
| Primary Use Case | Data analysis, data engineering, and machine learning | ETL (Extract, Transform, Load) workflows, data integration, and data migration |
| Core Technology | Apache Spark (big data processing) | Data integration service with connectors to various data sources |
| Programming | Supports Scala, Python, R, SQL | No direct programming required, mostly configuration-based |
| Collaboration | Collaborative workspace for data teams | Collaboration features for development and monitoring of data workflows |
| Data Transformation | Provides tools for data transformation within the platform | Data transformation happens within the data pipelines using Data Factory’s activities |
| Data Source/ Sink Connectivity | Connects to various data sources and destinations for analysis | Connects to various data stores and cloud services for data movement |
| Data Source/ Sink Connectivity | Provides support for real-time data processing | Offers some real-time data movement and transformation capabilities |
| Batch Processing | Supports batch processing for large-scale data | Primarily designed for batch-oriented data integration tasks |
| Advanced Analytics | Allows building and deploying machine learning models | Focused on data movement and orchestration, not advanced analytics |
| Use Case Example | Analyzing customer data for insights | Moving data from an on-premises database to a cloud data warehouse |
3. Describe Spark Architecture.
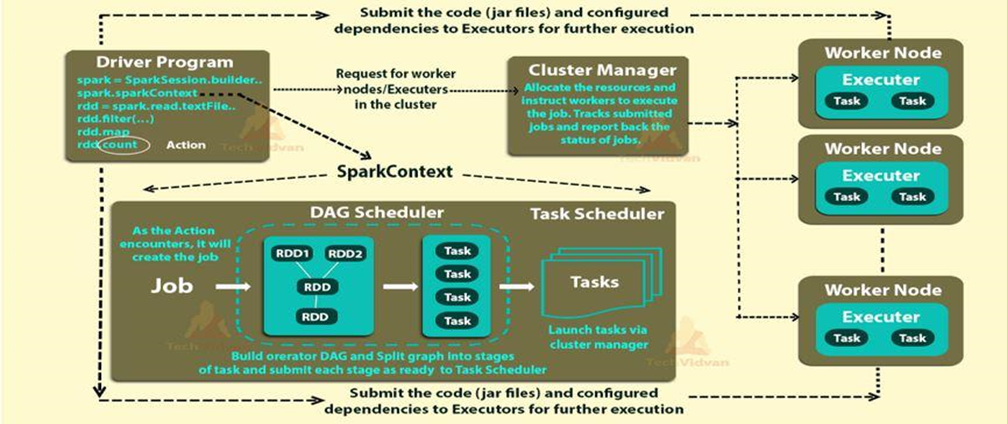
The architecture of an Apache Spark application is based on a distributed computing model that allows it to process large-scale data across multiple nodes in a cluster. Spark applications are designed to be fault-tolerant, scalable, and efficient. Here’s an overview of the key components and the flow of data in a typical Apache Spark application:
1. Driver Program:
- The Driver Program is the entry point of a Spark application. It runs on the master node and is responsible for creating the SparkContext, which is the entry point to any Spark functionality.
- The Driver Program defines the high-level control flow of the application, including tasks, stages, and dependencies between transformations and actions.
2. SparkContext (SC):
- SparkContext is the entry point to any Spark functionality. It establishes a connection to the cluster manager (e.g., YARN, Mesos, or Spark’s standalone cluster manager) to acquire resources for the application.
- The SparkContext coordinates with the Cluster Manager to allocate and manage executors across the worker nodes.
3. Cluster Manager:
- The Cluster Manager is responsible for managing the resources across the cluster, allocating tasks to workers, and ensuring fault tolerance.
- It can be YARN, Mesos, or Spark’s standalone cluster manager.
4. Worker Nodes:
- Worker Nodes are the machines in the cluster where actual data processing takes place.
- Each worker node hosts one or more executors, which are separate JVM processes responsible for executing tasks.
5. Executors:
- Executors are processes on the worker nodes responsible for executing individual tasks and storing data in memory or disk storage.
- They manage the data that is cached and reused across multiple Spark operations, reducing the need to read data from disk repeatedly.
6. Resilient Distributed Dataset (RDD):
- RDD is the fundamental data abstraction in Spark. It represents an immutable, fault-tolerant collection of objects that can be processed in parallel.
- RDDs are divided into partitions, and each partition is processed on a separate executor.
7. Transformations:
- Transformations are operations on RDDs that create new RDDs from existing ones. Examples include map, filter, reduceByKey, etc.
- Transformations are lazily evaluated, meaning they are not executed until an action is called.
8. Actions:
- Actions are operations that trigger the execution of transformations and return results to the Driver Program or write data to external storage.
- Examples of actions include collect, count, save, etc.
- Actions trigger the actual computation and materialize the RDD lineage.
9. Lineage Graph (DAG):
- Spark constructs a Directed Acyclic Graph (DAG) of the transformations (logical execution plan) and optimizes it before execution to minimize data shuffling and improve performance.
10. Data Sources and Sinks:
- Spark applications can read data from various sources (e.g., HDFS, S3, databases) and write data to external storage systems (e.g., HDFS, databases, file systems).
The architecture of Spark allows it to distribute data and computation across the cluster efficiently, providing fault tolerance, data locality, and high-performance data processing.
4. What is the maximum size of worker node you have used?
Storage 64 GB worker node.
Note – If you say more than that in interview garbage in and out problem occur so strict to max 64 GB.
5. How do you choose cluster configuration in Databrics?
- For normal ETL/ELT work – Memory optimize
- Quick Dev test – General Purpose
- For Shuffle intensive work(e.g lot many join) – Storage optimize
6. What is the difference between repartition and coalesce?
Both repartition and coalesce are Spark transformations used to control the distribution of data across partitions in a DataFrame or an RDD (Resilient Distributed Dataset). They affect how data is physically stored and distributed across the nodes of a cluster.
In summary, the key differences are:
- repartition can increase or decrease the number of partitions and performs a full data shuffle, while coalesce only reduces the number of partitions and tries to minimize data movement.
- Use repartition when you need to achieve a specific number of partitions or evenly distribute data for better parallelism. Use coalesce when you want to reduce the number of partitions efficiently without triggering a full shuffle.
# For DataFrame repartition df.repartition(numPartitions) # For DataFrame coalesce df.coalesce(numPartitions)
7. What is the drawback of coalesce?
The coalesce transformation in Spark is a powerful tool to reduce the number of partitions in a DataFrame or RDD without a full shuffle, which can be beneficial for certain use cases. However, it also has some drawbacks that you should be aware of:
Data Skew:
- When reducing the number of partitions with coalesce, Spark tries to minimize data movement and merges partitions into a smaller number of partitions. This approach can lead to data skew, where some partitions may end up with significantly more data than others.
- Data skew can negatively impact performance since a few partitions may become “hotspots” that are processed much slower than others, leading to inefficient resource utilization.
Uneven Data Distribution:
- Similar to data skew, coalesce can result in uneven data distribution across the reduced partitions. If the data has an uneven distribution or if certain keys have significantly more data than others, this can lead to suboptimal performance for subsequent operations like joins or aggregations.
Limited to Reduce Partitions:
- Unlike repartition, which allows you to increase or decrease the number of partitions, coalesce can only reduce the number of partitions. You cannot use coalesce to increase the number of partitions, which might be needed for certain operations that benefit from increased parallelism.
Less Parallelism:
- By reducing the number of partitions, you may reduce the level of parallelism in subsequent processing. This can lead to underutilization of resources, particularly if you have a large cluster with many available cores.
Optimal Partition Size:
- Choosing the right number of partitions for coalesce is crucial. If you set the number of partitions too low, you might end up with partitions that are too large to fit into memory, leading to performance issues.
8. If we have .gz file, how are they distributed in the spark
No, it will not be distributed, it will be single threaded.
9. What is the difference between “from pyspark.sql.type import *” and from pyspark.sql.types import xyz ?
Performance.
If we write from pyspark.sql.type import * every library under sql will get imported which will affect the performance.
10. What is the default partition size?

11. Have you worked on Databrics SQL? What is it all about?
Databrics SQL provides a simple experience for SQL users who wants to run quick ad-hoc queries on their data lake, create multiple visualization type to explore query result from different perspectives, and build and share dashboards.
12. What are the SQL endpoints? How are they different from cluster?
SQL endpoints in Databricks are secure entry points that allow users to execute SQL queries against their data. They provide a familiar SQL interface for querying and analyzing data stored in Databricks tables or external data sources like Delta Lake or Apache Spark tables.
Difference from cluster:
- A cluster in Databricks is a set of computing resources (e.g., virtual machines) used to run data processing and analytics workloads, such as Spark jobs and notebooks.
- SQL endpoints, on the other hand, are query interfaces specifically designed for executing SQL queries against data without the need to start a separate cluster.
- While clusters are general-purpose compute resources for various data processing tasks, SQL endpoints focus specifically on SQL query execution and can handle multiple concurrent queries efficiently.
13. What do you mean by interactive and job cluster?
Interactive Cluster: An interactive cluster in Databricks is designed for interactive data exploration and analysis. It provides a collaborative workspace where users can run notebooks and execute code interactively. Interactive clusters allow users to iteratively explore data, visualize results, and experiment with different analyses in a shared environment.
Job Cluster: A job cluster in Databricks is used for running batch jobs and automated data processing tasks. Unlike interactive clusters, job clusters are not continuously running and are launched on-demand to execute specific jobs at scheduled intervals or upon request. Job clusters are ideal for running ETL (Extract, Transform, Load) workflows, machine learning training, and other automated data processing tasks.
14. What is Auto scaling in databrics cluster?
- Auto Scaling in Databricks cluster automatically adjusts the cluster resources (number of worker nodes) based on workload demand, optimizing resource utilization and cost efficiency.
- Users can configure the Auto Scaling behaviour, setting minimum and maximum limits for the number of worker nodes and defining scaling policies based on metrics like CPU utilization or memory usage.
15. What is Managed and unmanaged tables in databrics?
In Databricks, managed and unmanaged tables are two different ways of organizing and managing data in the Databricks Delta Lake or Apache Spark table format:
Managed Tables:
- Managed tables, also known as Delta tables, are tables whose metadata and data files are managed and controlled by Databricks.
- When you create a managed table, Databricks handles the storage, organization, and cleanup of data files and metadata automatically.
- This means that when you delete a managed table, Databricks will also delete all the associated data files from storage.
- Managed tables are easy to work with since Databricks takes care of most of the underlying management tasks.
Unmanaged Tables:
- Unmanaged tables are tables where you have direct control over the data files, and Databricks does not manage the data or metadata.
- When you create an unmanaged table, you need to specify the data files’ location, and Databricks relies on you to handle file organization and cleanup.
- If you delete an unmanaged table, Databricks only removes the metadata, but the data files remain intact in the specified location.
- Unmanaged tables provide more control over the data, making them suitable for scenarios where you have existing data files in a specific location.
In summary, managed tables are automatically managed by Databricks, including data file storage and cleanup, while unmanaged tables require you to handle the data files’ management and organization manually.
16. How do you configure numbers of core in worker?
Generally, Number of cores = Numbers of partitions.
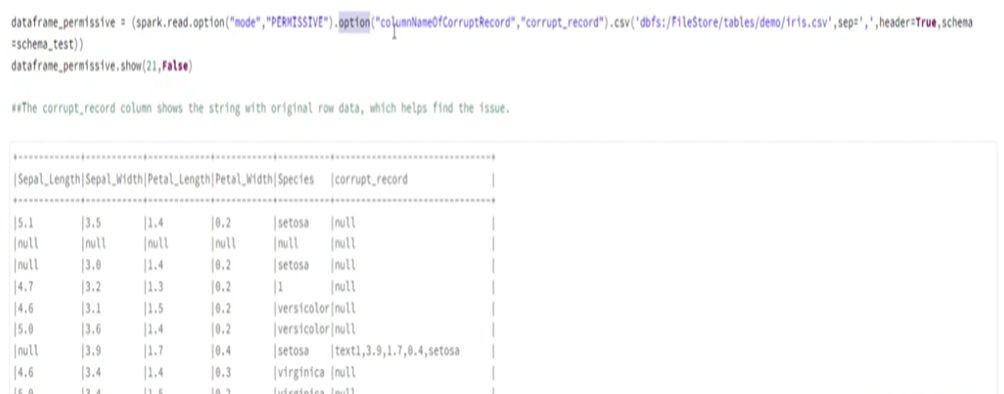
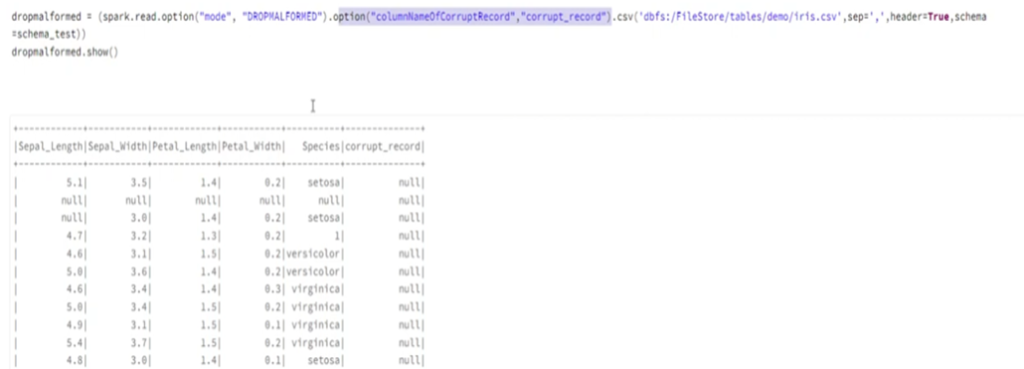
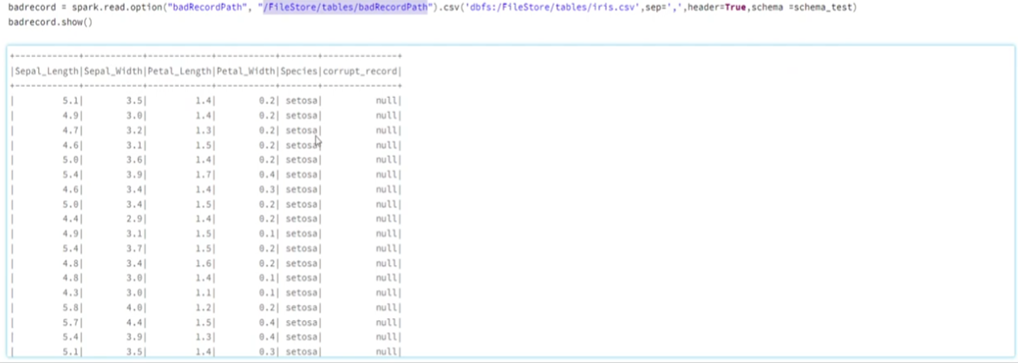
17. How do you handle BAD records in databrics?
There are two ways to handle errors in databrics:
MODE:
- Permissive(Error value will be stored as null and entire error row will be saved as column)
- Dropmalformed (Whole records that has error values will get drop off)
- Failfast(When error is recognized execution stops)
BAD RECORD PATH (Redirect value to separate path)
18. Given a list of json string, count the number of IP address, order of output does not matter?
To count the number of unique IP addresses from a list of JSON strings, you can follow these steps
- Parse the JSON strings and extract the IP addresses.
- Use a set to store the unique IP addresses.
- Count the number of elements in the set, which will give you the count of unique IP addresses.
Here’s the Python code to achieve this:
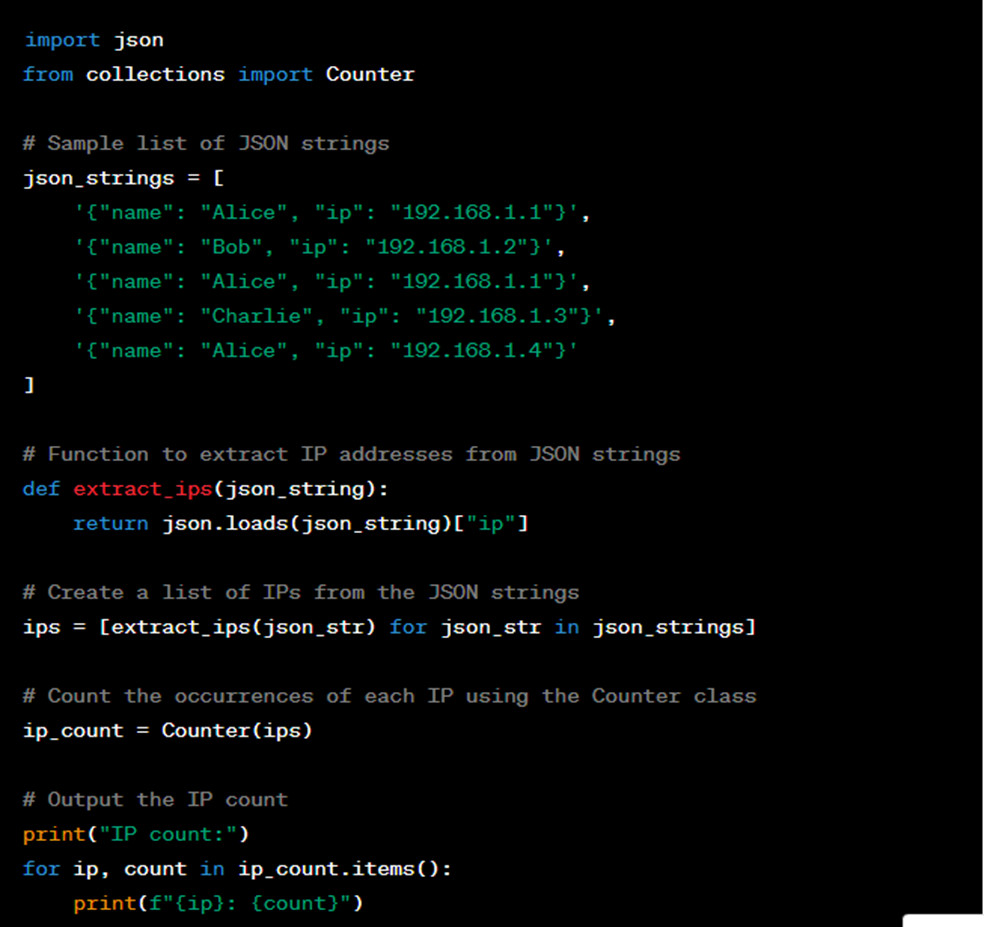
Output:

19. What is difference between narrow and wide transformation?
In Databricks (and Apache Spark), transformations are operations performed on a distributed dataset (RDD or DataFrame). These transformations are broadly classified into two categories: narrow transformations and wide transformations.
1. Narrow Transformations:
- Narrow transformations are transformations where each input partition contributes to at most one output partition.
- These transformations do not require data to be shuffled across the partitions, and they can be performed in parallel on each partition independently.
- Examples of narrow transformations include `map`, `filter`, and `union`.
2. Wide Transformations:
- Wide transformations are transformations where each input partition can contribute to multiple output partitions.
- These transformations require data to be shuffled and redistributed across the partitions, which involves a data exchange between the worker nodes.
- Wide transformations usually result in a stage boundary, which involves a physical data exchange and a shuffle operation.
- Examples of wide transformations include `groupBy`, `join`, and `sortByKey` (for RDDs).
The main difference between narrow and wide transformations lies in how they handle data distribution and shuffling. Narrow transformations can be executed efficiently in a parallel and distributed manner without the need for shuffling data between partitions. On the other hand, wide transformations require a data shuffle, which can be a more expensive operation as it involves network communication and data redistribution.
To optimize Spark job performance, it’s essential to minimize the usage of wide transformations and use them judiciously. When designing data processing pipelines, try to keep as many transformations as possible as narrow transformations to reduce data shuffling and improve execution efficiency.
20. What is shuffle? why shuffle occur? What causes the shuffle?
In the context of Apache Spark (and Databricks), a “shuffle” refers to the process of redistributing data across partitions in a distributed computing environment. Shuffle occurs when data needs to be rearranged to satisfy a specific operation, such as aggregations, joins, or sorting, where data from multiple partitions needs to be brought together to perform the operation effectively.
Shuffle occurs for the following reasons:
1. Data Reorganization for Operations:
- Certain operations, like grouping elements by a key in a `groupBy` or performing a `join` between two datasets, require data with the same keys to be brought together into the same partition to perform the operation.
- For example, when you perform a `groupBy` on a DataFrame or RDD based on a particular column, Spark needs to gather all the rows with the same key from various partitions and organize them together.
2. Data Skew:
- Data skew occurs when the distribution of data across partitions is uneven, causing some partitions to have significantly more data than others.
- In scenarios with data skew, a few partitions can become overloaded with data, leading to slower processing times for those partitions and suboptimal resource utilization.
- To handle data skew, Spark may need to redistribute data through shuffle to achieve a more balanced data distribution across partitions.
3. Performance Optimization:
- In some cases, shuffle can be used to optimize performance by co-locating related data on the same partitions, reducing the amount of data exchange during certain operations.
- For example, Spark can leverage shuffle to bring together data that will be accessed together, reducing the need to read data from various partitions separately.
It’s essential to be aware of the cost of shuffle operations since they involve data movement across the network, which can be expensive in terms of computation and time. Minimizing shuffle whenever possible is a key performance consideration when designing and optimizing Apache Spark or Databricks jobs. Proper partitioning of data and careful selection of appropriate operations can help reduce the frequency and impact of shuffling.
21. What is difference between sortBy and OrderBy?
We can use either sort() or Orderby() built in function to sort a particular dataframe in a ascending or descending order over at least one column.
Sort()
Sort() method will sort() the records in each partition and then return the final output which means that the order of the output data is not guaranteed because data is ordered on partition level but your data frame may have thousands of partitions distributed across the cluster.
Since the data is not collected into a single executor the sort() method is efficient thus more suitable when sorting is not critical for your use case.
Orderby()
Unlike Sort(), the orderBy() function guarantee a total order in the output. This happen because the data will be collected into a single executor in order to be sorted.
This means that orderBy() is more inefficient compared to sort()
22. What is difference between map and map partition?
map()
map is a transformation that applies a function to each element of the RDD or DataFrame, processing the elements one at a time. whatever transformation you mentation on the data. It has a one-to-one mapping between input and output elements.
mapPartitions()
mapPartitions is a transformation that applies a function to each partition of the RDD or DataFrame, processing multiple elements within each partition at once. It has a one-to-many mapping between input partitions and output partitions.
In summary, map processes data element-wise, while mapPartitions processes data partition-wise, which can lead to more efficient data processing when dealing with expensive operations or when you need to maintain some state across multiple elements within a partition.
23. What is lazy evaluation in spark?
Lazy evaluation in Spark refers to the evaluation strategy where transformations on RDDs (Resilient Distributed Datasets) or DataFrames are not executed immediately when called. Instead, Spark builds up a logical execution plan (DAG – Directed Acyclic Graph) representing the sequence of transformations. The actual execution is deferred until an action is called.
Key points about lazy evaluation in Spark:
Transformations are Deferred:
When you apply a transformation on an RDD or DataFrame (e.g., `map`, `filter`, `groupBy`, etc.), Spark does not perform the actual computation right away. Instead, it records the transformation in the execution plan.
Logical Execution Plan (DAG):
Spark builds a directed acyclic graph (DAG) that represents the series of transformations in the order they were applied. Each node in the DAG represents a transformation, and the edges represent data dependencies.
Efficient Optimization:
Since Spark has access to the entire transformation sequence before executing any action, it can optimize the execution plan for performance, by combining and reordering transformations to reduce data shuffling and improve parallelism.
Lazy Execution with Actions:
Spark only performs the actual computation when an action is called (e.g., `collect`, `count`, `save`, etc.). Actions trigger the execution of the entire DAG of transformations, starting from the original RDD or DataFrame.
Benefits of lazy evaluation:
- It allows Spark to optimize the execution plan before actually running the job, leading to more efficient data processing.
- Lazy evaluation reduces unnecessary computation and data shuffling, as Spark can skip intermediate transformations that are not needed to compute the final result.
- It provides an opportunity for developers to chain multiple transformations together before triggering the actual computation, which can lead to more concise and modular code.
Overall, lazy evaluation is a fundamental optimization technique in Spark that improves performance by deferring the execution of transformations until the results are required.
24. What are the different levels of persistence in spark?
In Apache Spark, persistence (also known as caching) is a technique to store intermediate or final computation results in memory or disk. By persisting data, Spark can reuse it across multiple Spark operations without re-computing it from the original data source. This can significantly improve the performance of iterative algorithms or when the same data is accessed multiple times.
There are different levels of persistence available in Spark:
1. MEMORY_ONLY (or MEMORY_ONLY_SER):
- This is the simplest level of persistence, where the RDD or DataFrame is stored in memory as deserialized Java objects (MEMORY_ONLY) or serialized bytes (MEMORY_ONLY_SER).
- MEMORY_ONLY is suitable when the data fits comfortably in memory and can be quickly accessed without deserialization overhead.
- MEMORY_ONLY_SER is useful when the data size is larger than the available memory, as it saves memory space by keeping the data in a serialized format.
2. MEMORY_AND_DISK:
- In this level of persistence, if an RDD or DataFrame does not fit entirely in memory, Spark spills the excess partitions to disk while keeping the remaining partitions in memory.
- MEMORY_AND_DISK provides a balance between in-memory access speed and disk space utilization. However, accessing data from disk is slower than accessing it from memory, so it may lead to performance degradation for frequently accessed data that spills to disk.
3. MEMORY_AND_DISK_SER:
- Similar to MEMORY_AND_DISK, but it stores data in serialized format to save memory space.
- MEMORY_AND_DISK_SER can be beneficial when the dataset is large and cannot fit entirely in memory.
4. DISK_ONLY:
- In this level of persistence, data is stored only on disk and not kept in memory.
- DISK_ONLY is suitable when memory is limited, and the data size is much larger than the available memory.
- Accessing data from disk is slower than accessing it from memory, so performance might be affected.
5. OFF_HEAP:
- This is an experimental feature in Spark that stores data off-heap (outside the JVM heap space).
- OFF_HEAP is useful for very large datasets that require a significant amount of memory, as it can help avoid Java garbage collection overhead.
Each persistence level offers different trade-offs between memory utilization and access speed. The choice of persistence level depends on factors like the size of data, available memory, and the frequency of data access in your Spark application. Properly selecting the persistence level can greatly impact the overall performance and efficiency of Spark jobs.
Import org.apache.spark.storage.storagelevel
Val rdd2 = rdd.persist(StorageLevel.MEMORY_ONLY)
25. How to check data skewness of how many rows present in each partition?
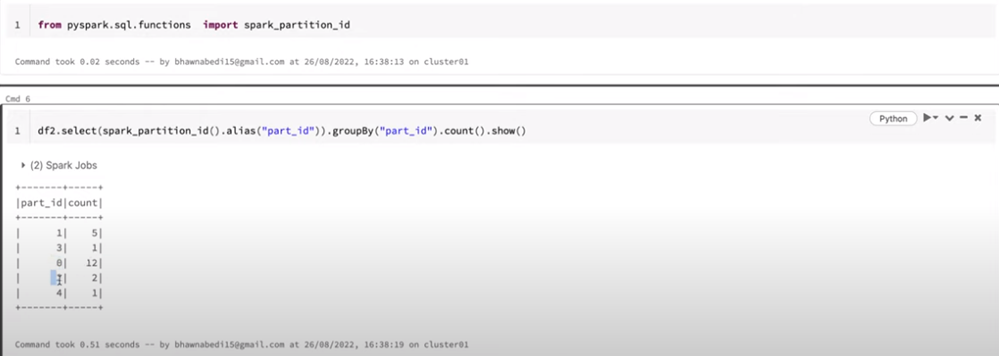

26. What are the different planes in Databrics?
In cloud computing and distributed systems, the concept of “planes” is used to categorize different aspects of the system’s architecture and management. The three main planes are:
Data Plane:
- The Data Plane is responsible for handling and processing the actual user data and performing the intended operations on the data.
- In Databricks, the Data Plane is where data processing tasks take place, such as executing Spark jobs, running notebooks, and performing data transformations.
Control Plane:
- The Control Plane is responsible for managing and coordinating the overall system’s operation and behavior.
- In Databricks, the Control Plane manages the cluster lifecycle, monitors resource allocation, schedules jobs, and handles administrative tasks such as authentication, access control, and cluster management.
Management Plane:
- The Management Plane provides tools and interfaces for users and administrators to configure, monitor, and manage the system and its components.
- In Databricks, the Management Plane includes the Databricks Workspace, which provides a collaborative environment for managing notebooks, libraries, dashboards, and other resources.
Each plane plays a crucial role in the operation and management of cloud-based distributed systems like Databricks, helping to separate concerns and provide a clear and organized way to design and manage complex systems.
27. How to drop duplicate from following dataframe?
| STATION_ID | DATE_CHANGED STATION_ID |
| 1 | 6/7/2006 6:00 |
| 1 | 9/26/2000 6:00 |
| 2 | 7/29/2005 6:00 |
| 2 | 6/6/2001 6:00 |
| 4 | 6/8/2001 6:00 |
| 4 | 11/25/2003 7:00 |
| 7 | 6/12/2001 6:00 |
| 8 | 6/4/2001 6:00 |
| 8 | 4/3/2017 18:36 |
df.sort_values('DATE_CHANGED').drop_duplicates('STATION_ID',keep='last')28. How to improve performance of a notebook in databrics?
To improve notebook performance in Databricks, you can follow these best practices and optimization techniques:
1. Cluster Configuration: Use an appropriately sized cluster based on your workload. Scaling up the cluster can significantly improve performance, especially for resource-intensive tasks. Databricks provides various cluster types with different CPU, memory, and GPU configurations. You can monitor cluster performance to identify bottlenecks.
2. Autoscaling: Enable autoscaling to automatically adjust the number of workers based on the workload. This helps optimize resource allocation and reduce costs during idle periods.
3. Caching and Persistence: Utilize caching and persistence to store intermediate results or dataframes that are frequently accessed. This can speed up subsequent operations by avoiding redundant computations.
4. Optimize Data Format: Choose appropriate data formats to store and read data. For example, using Parquet format for storage is more efficient than using CSV or JSON due to its columnar storage and compression capabilities.
5. Limit Data Shuffling: Minimize data shuffling as it can be a resource-intensive operation. Data shuffling occurs when the data needs to be redistributed across partitions, and it can impact performance significantly.
6. Tune Spark Configurations: Adjust Spark configurations like `spark.sql.shuffle.partitions`, `spark.executor.memory`, and `spark.driver.memory` to optimize performance based on your specific workload and data size.
7. Use Delta Lake: If possible, leverage Delta Lake for transactional and versioned data storage. It offers significant performance improvements for analytics workloads.
8. Spark UI Optimization: Use the Spark UI to monitor job progress, identify performance bottlenecks, and optimize query plans. Look for stages with long execution times or high shuffle data, and try to optimize them.
9. Use Databricks Runtime: Databricks Runtime is optimized by default and includes various performance improvements. Always use the latest stable version for the best performance and new features.
10. Notebook Code Optimization: Review and optimize your notebook code regularly. Avoid unnecessary data transformations and use efficient Spark APIs and DataFrame operations when possible.
11. Resource Management: Be mindful of resource utilization in notebooks. Avoid running multiple long-running notebooks simultaneously to prevent resource contention.
12. Data Pruning: For large datasets, consider pruning the data to limit the amount of data processed, especially if you only need a specific time range or subset of data.13. External Data Cache: Use the Databricks External Data Cache to cache data across multiple notebooks or clusters, reducing data transfer time and computation overhead.
Remember that the effectiveness of these optimizations depends on your specific use case and data, so it’s essential to monitor and fine-tune your configurations regularly to achieve the best performance.
29. How to pass parameter though parent notebook in the child notebook?
In Databricks, you can pass parameters from a parent notebook to a child notebook using the dbutils.notebook.run function. This function allows you to call a child notebook and pass parameters as input to the child notebook. Here’s a step-by-step guide on how to do this.
Step 1: Define the Parent Notebook:
In the parent notebook, you can define the parameters you want to pass to the child notebook and then call the child notebook using the dbutils.notebook.run function.
# Parent Notebook
param1 = "value1"
param2 = 42
dbutils.notebook.run("ChildNotebook", 0, {"param1": param1, "param2": param2})
Step 2: Access Parameters in the Child Notebook:
In the child notebook, you can access the parameters passed from the parent notebook using the dbutils.widgets module. You need to define widgets with the same names as the parameters used in the parent notebook.
# ChildNotebook
param1 = dbutils.widgets.get("param1")
param2 = dbutils.widgets.get("param2")
print("Received parameters in child notebook:")
print("param1:", param1)
print("param2:", param2)
By using the dbutils.widgets.get function with the same name as the parameter, you can retrieve the values passed from the parent notebook.
30. What are the dbutils function available in databrics?
In Databricks, the `dbutils` module provides utility functions that help you interact with the Databricks environment, access files, manage libraries, and more. These functions are designed to simplify common tasks when working with Databricks notebooks and clusters. Here are some of the commonly used `dbutils` functions available in Databricks:
1. File System Operations:
- dbutils.fs.ls(path): List files in a directory.
- dbutils.fs.cp(source, destination): Copy a file or directory.
- dbutils.fs.mv(source, destination): Move or rename a file or directory.
- dbutils.fs.rm(path, recurse=True): Remove a file or directory.
- dbutils.fs.mkdirs(path): Create directories recursively.
2. Notebook Utilities:
– `dbutils.notebook.run(notebook_path, timeout_seconds, arguments)`: Run a different notebook and pass parameters.
– `dbutils.notebook.exit(result)`: Stop execution of the current notebook and return a result.
3. Widgets:
– dbutils.widgets.text(name, defaultValue): Create a text widget.
– dbutils.widgets.get(name): Get the value of a widget.
– dbutils.widgets.dropdown (name, defaultValue, choices): Create a dropdown widget.
– dbutils.widgets.combobox (name, defaultValue, choices): Create a combo box widget.
– dbutils.widgets.multiselect (name, defaultValue, choices): Create a multiselect widget.
4. Library Management:
– dbutils.library.install (pypi_package): Install a PyPI package as a library.
– dbutils.library.restartPython(): Restart the Python interpreter to apply library changes.
– dbutils.library.remove (library_path): Remove a library.
5. Secret Management:
– dbutils.secrets.get(scope, key): Retrieve a secret from the Databricks Secret Manager.
6. Azure Blob Storage Utilities:
– dbutils.fs.mount(source, mount_point): Mount an Azure Blob Storage container.
– dbutils.fs.unmount(mount_point): Unmount an Azure Blob Storage container.
31. What is broadcast join?
In Databricks, a broadcast join is a type of join operation used in Spark SQL that optimizes the performance of joining a small DataFrame (or table) with a larger DataFrame (or table). It is based on the concept of broadcasting the smaller DataFrame to all the nodes of the cluster, allowing each node to perform the join locally without shuffling the data. This approach is beneficial when one of the DataFrames is small enough to fit in memory and the other DataFrame is significantly larger.
When performing a broadcast join, Spark automatically broadcasts the smaller DataFrame to all the worker nodes in the cluster, making it available in memory. Then, the worker nodes use this broadcasted copy to perform the join locally with their respective partitions of the larger DataFrame. By doing so, Spark can avoid costly shuffling operations, which can lead to significant performance improvements.
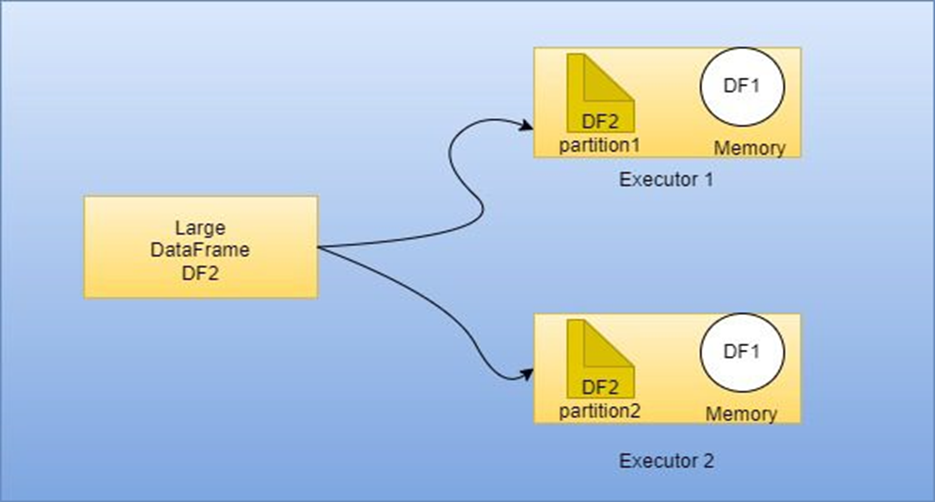
To leverage the benefits of a broadcast join in Spark SQL, you can explicitly hint the optimizer to use it for a specific join by using the BROADCAST keyword. For example:

By adding the /*+ BROADCAST(small_df) */ hint to the SQL query, you inform Spark to use a broadcast join for the specified small_df DataFrame.
32. What is struct function?
In Databricks, the struct function is a Spark SQL function used to create a new struct column by combining multiple columns together. A struct column is similar to a struct or namedtuple in programming languages, allowing you to group multiple values together into a single column. This is especially useful when you want to create complex data types or nest multiple fields within a single DataFrame column.
The struct function takes multiple column expressions as arguments and returns a new column containing the combined values as a struct. Each input column becomes a field within the resulting struct column. The struct columns can then be used like any other DataFrame column, allowing you to access nested data in a structured manner.
Here’s the basic syntax of the struct function:

- column1, column2, …, columnN: The input columns that you want to combine into the struct column.
Here’s a practical example of using the struct function:
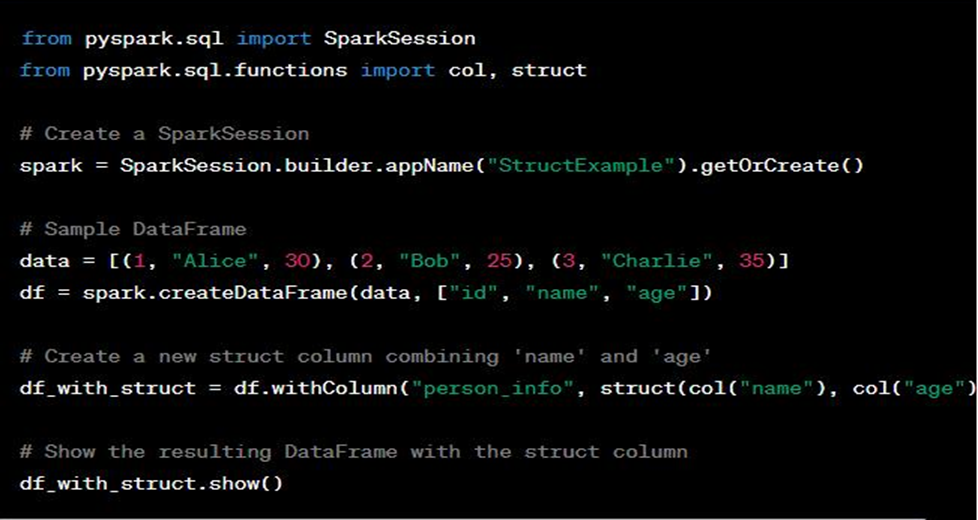
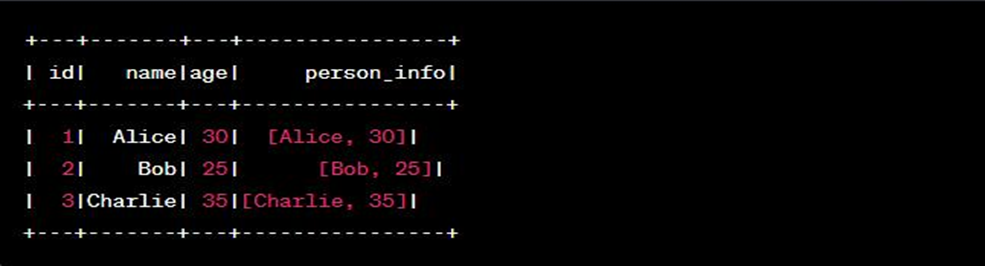
Output look like this:
33. What is explode function does?
In Databricks, the explode function is a Spark SQL function used to transform an array or map column into multiple rows, effectively “exploding” the elements of the array or map into separate rows. This is particularly useful when you have data with nested arrays or maps, and you want to flatten the structure to perform operations on individual elements.
The explode function works on columns that contain arrays or maps and produces a new DataFrame with each element of the array or map expanded into separate rows. For arrays, each element of the array becomes a separate row, and for maps, the key-value pairs of the map become separate rows.
Here’s the basic syntax of the explode function:

- column: The column containing the array or map that you want to explode.
- alias: An optional alias to give a name to the resulting column after the explosion.
Let’s look at a practical example using the explode function:
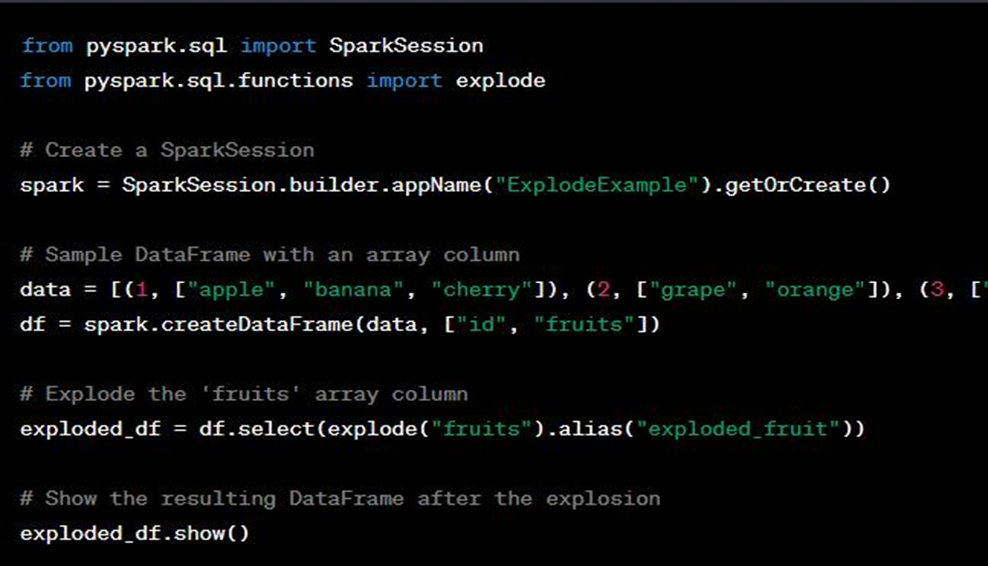
The output will look like:
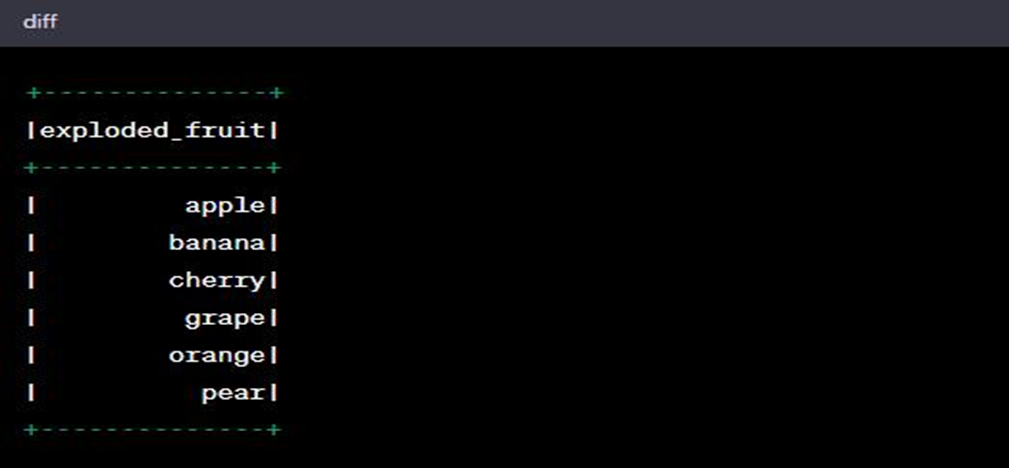
As you can see, the fruits array column is exploded into separate rows, where each fruit from the array becomes an individual row in the resulting DataFrame.
The explode function is a powerful tool when working with nested data structures, and it allows you to perform operations on individual elements within arrays or maps efficiently in Databricks. It can be combined with other Spark SQL functions to perform complex data manipulations on nested data.
34. Is it possible to combine Databricks and Azure Notebooks?
They operate similarly, but data transfer to the cluster requires manual coding. This Integration is now easily possible thanks to Databricks Connect. On behalf of Jupyter, Databricks makes a number of improvements that are specific to Databricks.
35. What exactly does caching entail?
Temporary holding is referred to as the cache. The process of temporarily storing information is referred to as caching. You’ll save time and lessen the load on the server when you come back to a frequently visited website because the browser will retrieve the data from the cache rather than from the server.
36. What are the different types of caching are there?
There are four types of caching that stand out:
- Information caching
- Web page caching
- Widespread caching
- Output or application caching.
37. Should you ever remove and clean up any leftover Data Frames?
Cleaning Frames is not necessary unless you use cache(), which will use a lot of network bandwidth. You should probably clean up any large datasets that are being cached but aren’t being used.
38. What different ETL operations does Azure Databricks carry out on data?
The various ETL processes carried out on data in Azure Databricks are listed below:
- The data is converted from Databricks to the data warehouse.
- Bold storage is used to load the data.
- Data is temporarily stored using bold storage
39. Does Azure Key Vault work well as a substitute for Secret Scopes?
That is certainly doable. However, some setup is necessary. The preferred approach is this. Instead of changing the defined secret, start creating a scoped password that Azure Key Vault will backup if the data in secret needs to be changed.
40. How should Databricks code be handled when using TFS or Git for collaborative projects?
TFS is not supported, to start. Your only choices are dispersed Git repository systems and Git. Although it would be ideal to integrate Databricks with the Git directory of notebooks, it works much like a different project clone. Making a notebook, trying to commit it to version control, and afterwards updating it are the first steps.
41. Does Databricks have to be run on a public cloud like AWS or Azure, or can it also run on cloud infrastructure?
This is not true. The only options you have right now are AWS and Azure. But Databricks uses Spark, which is open-source. Although you could build your own cluster and run it in a private cloud, you’d be giving up access to Databricks’ robust features and administration.
42. How is a Databricks personal access token created?
- On the Databricks desktop, click the “user profile” icon in the top right corner.
- Choosing “User setting.”
- Activate the “Access Tokens” tab.
- A “Generate New Token” button will then show up. Just click it.
43. Is code reuse possible in the Azure notebook?
We should import the code first from Azure notebook into our notebook so that we can reuse it. There are two ways we can import it.
- We must first create a component for the code if it is located on a different workstation before integrating it into the module.
- We can import and use the code right away if it is on the same workstation.
44. What is a Databricks cluster?
The settings and computing power that make up a Databricks cluster allow us to perform statistical science, big data, and powerful analytic tasks like production ETL, workflows, deep learning, and stream processing.

45. Is databrics provide database services, if no then where it saves the delta table?
Azure Databricks does not directly provide traditional database services like SQL Server or Azure SQL Database. Instead, it is an Apache Spark-based analytics platform designed to process and analyze big data workloads. However, it can work with various data sources and databases to perform data processing and analytics tasks.
One of the popular data storage options in Azure Databricks is Delta Lake, which is an open-source storage layer that brings ACID (Atomicity, Consistency, Isolation, Durability) transactions to data lakes. Delta Lake provides some database-like functionalities on top of cloud storage systems like Azure Data Lake Storage or Azure Blob Storage.
When you save a Delta table in Azure Databricks, the data is typically stored in your specified cloud storage (e.g., Azure Data Lake Storage or Azure Blob Storage). Delta Lake keeps track of the changes made to the data, allowing for versioning and transactional capabilities.
46. Is Databricks only available in the cloud and does not have an on-premises option?
Yes. Databricks’ foundational software, Apache Spark, was made available as an on-premises solution, allowing internal engineers to manage both the data and the application locally. Users who access Databricks with data on local servers will encounter network problems because it is a cloud-native application. The on-premises choices for Databricks are also weighed against workflow inefficiencies and inconsistent data.
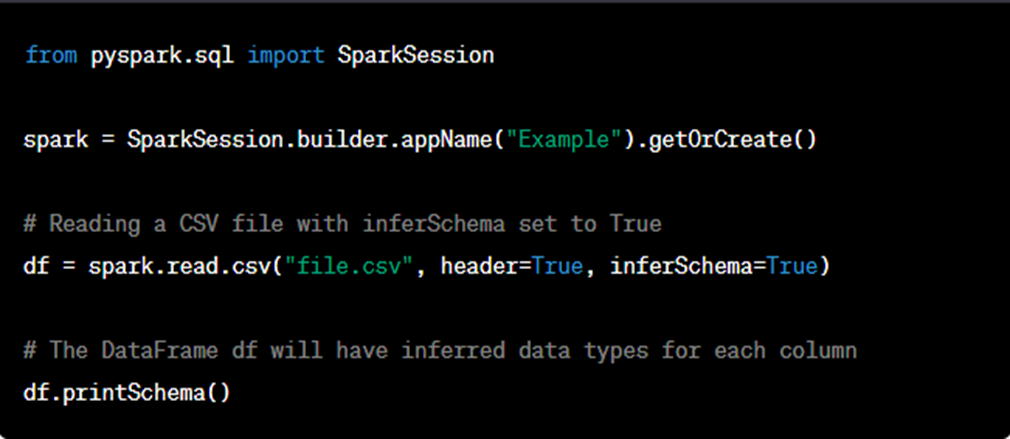
47. In Parameter what does it mean by inferSchema as True
In the context of data processing frameworks like Apache Spark and PySpark (used in Azure Databricks), the inferSchema parameter is used when reading data from external sources like CSV, JSON, Parquet, etc. It is a configuration option that determines whether Spark should automatically infer the data types of the columns in the DataFrame based on the data content.
When inferSchema is set to True, Spark will automatically examine a sample of the data to infer the data types for each column. This process involves analyzing the data values in each column and making educated guesses about the appropriate data types. For example, if a column predominantly contains numeric values, Spark might infer it as an integer or a double data type. Similarly, if a column primarily contains strings, it might infer it as a string data type.
Setting inferSchema to True can be convenient and save time, especially when working with large datasets with many columns. Spark’s ability to automatically infer data types allows you to read data without explicitly specifying the schema, making the code shorter and more flexible.
However, it’s essential to be cautious when using inferSchema, as it relies on a sample of the data and might not always make accurate decisions, especially when the data is sparse or there are outliers. In such cases, it’s recommended to provide an explicit schema to ensure the correct data types are used.
48. What are the difference between Auto Loader vs COPY INTO?
Auto Loader:
Auto Loader incrementally and efficiently processes new data files as they arrive in cloud storage without any additional setup. Auto Loader provides a new Structured Streaming source called cloudFiles. Given an input directory path on the cloud file storage, the cloudFiles source automatically processes new files as they arrive, with the option of also processing existing files in that directory.
When to use Auto Loader instead of the COPY INTO?
- If you’re going to ingest files in the order of thousands, you can use COPY INTO. If you are expecting files in the order of millions or more over time, use Auto Loader. Auto Loader requires fewer total operations to discover files compared to COPY INTO and can split the processing into multiple batches, meaning that Auto Loader is less expensive and more efficient at scale.
- If your data schema is going to evolve frequently, Auto Loader provides better primitives around schema inference and evolution. See Configure schema inference and evolution in Auto Loader for more details.
- Loading a subset of re-uploaded files can be a bit easier to manage with COPY INTO. With Auto Loader, it’s harder to reprocess a select subset of files. However, you can use COPY INTO to reload the subset of files while an Auto Loader stream is running simultaneously.
spark.readStream.format("cloudfiles") # Returns a stream data source, reads data as it arrives based on the trigger.
.option("cloudfiles.format","csv") # Format of the incoming files
.option("cloudfiles.schemalocation", "dbfs:/location/checkpoint/") The location to store the inferred schema and subsequent changes
.load(data_source)
.writeStream.option("checkpointlocation","dbfs:/location/checkpoint/") # The location of the stream’s checkpoint
.option("mergeSchema", "true") # Infer the schema across multiple files and to merge the schema of each file. Enabled by default for Auto Loader when inferring the schema.
.table(table_name)) # target table
49. How to do partition data in the databrics?
Partitioning data in Databricks, or any other data processing platform, can greatly improve query performance and overall data organization. Partitioning involves dividing your data into smaller, more manageable parts based on specific criteria, such as a particular column’s values. This helps reduce the amount of data that needs to be scanned when executing queries, leading to faster query execution times. Here’s how you can partition data in Databricks:
1. Choose a Partition Column: Select a column in your dataset that you want to use for partitioning. Common choices are date columns, country codes, or any other attribute that can be used to logically group your data.
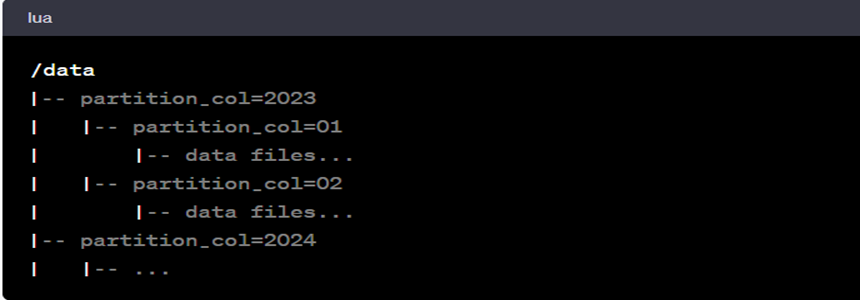
2. Organize Data: Arrange your data in the storage system (like a data lake) in a way that reflects the partitioning scheme you’ve chosen. This usually involves creating subdirectories for each partition, where the name of the subdirectory corresponds to the partition key’s value. For example, if you’re partitioning by year and month, your directory structure might look like:
3. Write Partitioned Data: When writing data into Databricks, make sure to specify the partition column and value appropriately. Databricks has integrations with various data sources like Parquet, Delta Lake, and more, which support partitioning.
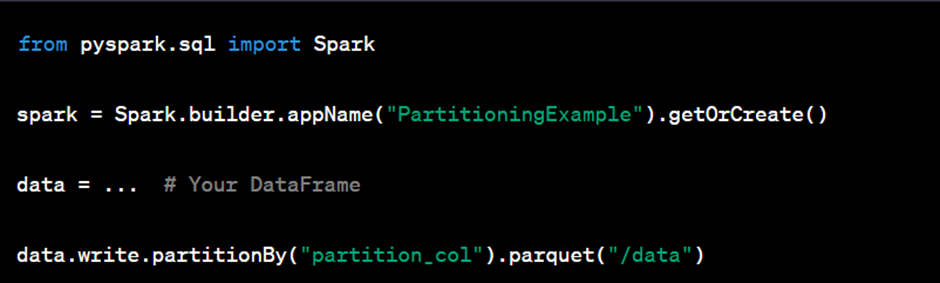
For example, if you’re using Apache Spark to write partitioned Parquet data, you can do something like this:
4. Querying Partitioned Data: When querying partitioned data, Databricks and Spark will automatically take advantage of the partitioning scheme to optimize query performance. You can filter your queries based on the partition column, and Spark will only scan the relevant partitions, reducing the amount of data scanned.
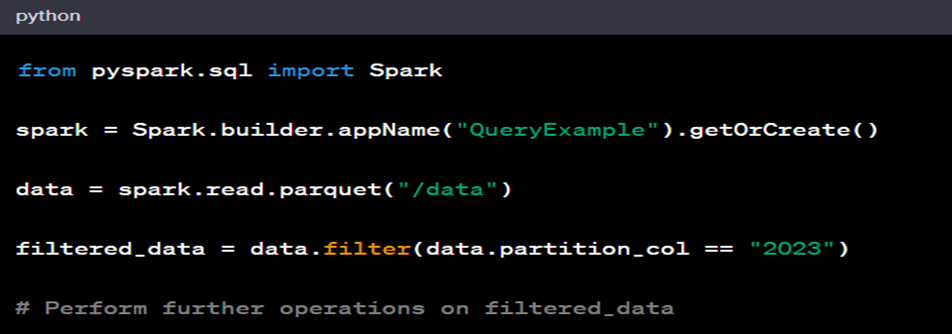
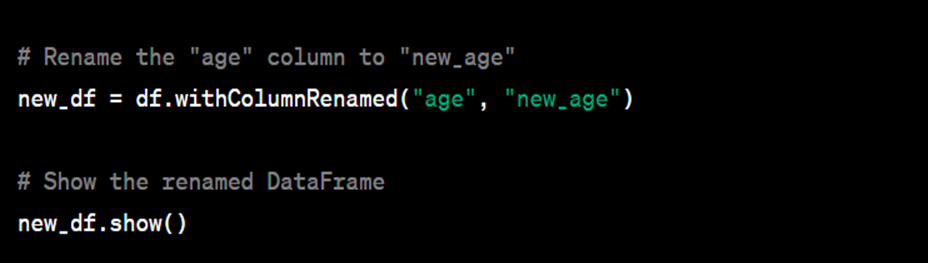
50. How to rename a column name in dataframe?
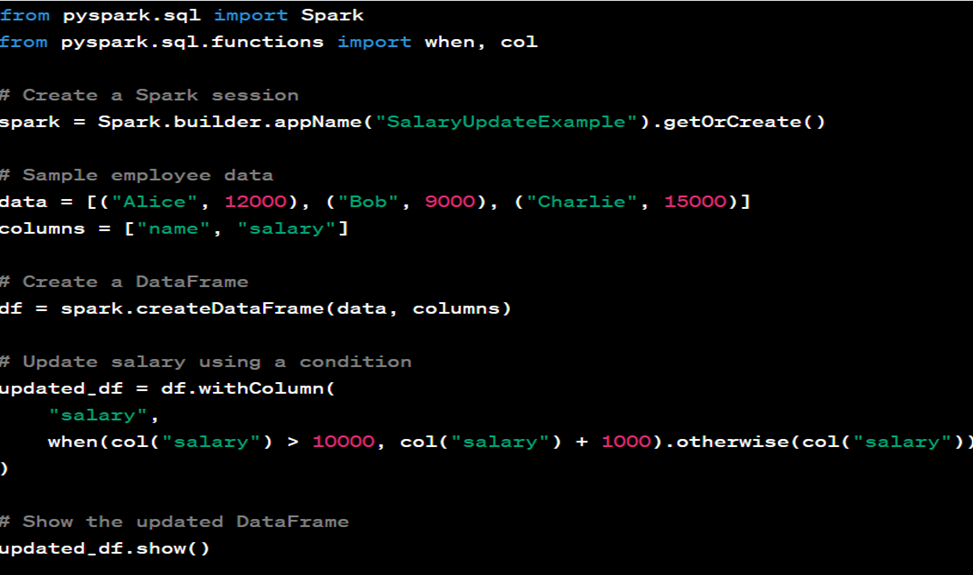
51. If we have an employee data frame and we want to add 1000 to those employee’s salary who have a more than 10,000 salary how to do that?
You can achieve this using PySpark by applying a transformation to the DataFrame to update the salary values based on a condition. Here’s a sample code to add 1000 to the salary of employees who have a salary greater than 10,000:
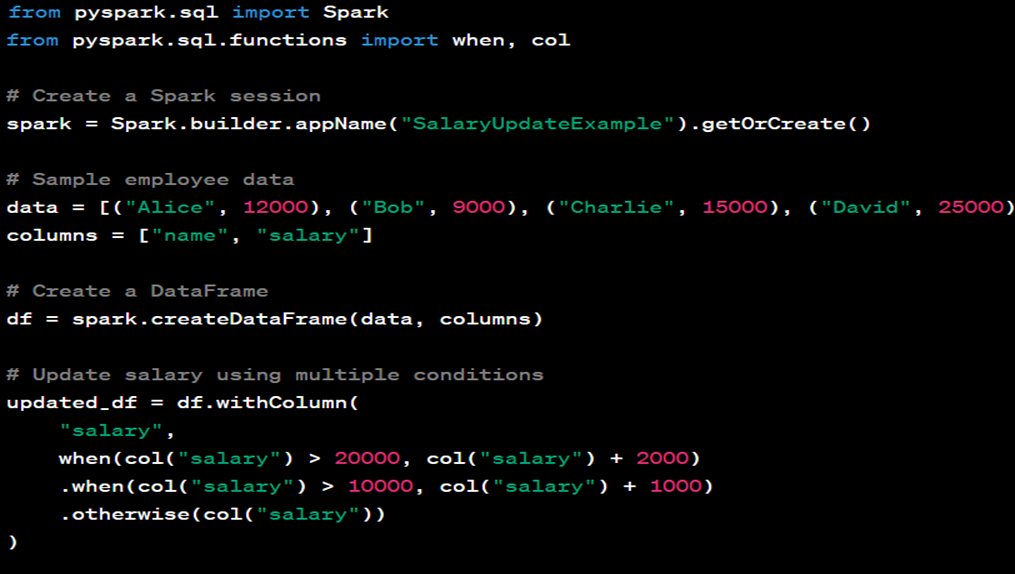
Update using multiple conditions.
52. What is surrogate key in database concept?
A surrogate key is a unique identifier that is added to a database table to serve as a primary key. Unlike natural keys, which are based on existing data attributes (such as names, dates, or other real-world information), surrogate keys are typically artificially created and have no inherent meaning. They are used primarily to improve the efficiency and performance of database operations.
Surrogate keys offer several benefits:
1. Uniqueness: Surrogate keys are generated in a way that ensures their uniqueness across the entire table. This eliminates the risk of duplicate entries that might occur with natural keys.
2. Stability: Since surrogate keys are not based on changing attributes like names or addresses, they remain stable over time. This makes them ideal for linking data and maintaining relationships even when other attributes change.
3. Performance: Surrogate keys can improve database performance by making indexes and joins more efficient. They tend to be shorter than meaningful attributes, leading to faster data retrieval and better query performance.
4. Data Privacy: Surrogate keys help maintain data privacy by not exposing sensitive or personal information in the key itself. This can be important for compliance with data protection regulations.
5. Simplifying Joins: When tables are linked through relationships, using surrogate keys can simplify the process of joining tables, as the keys are consistent and predictable.
6. Data Warehousing: In data warehousing scenarios, surrogate keys are often used to create fact and dimension tables, facilitating efficient reporting and analysis.
An example of a surrogate key might be an auto-incrementing integer that is assigned to each new record added to a table. This key is unique and has no inherent meaning, making it an ideal primary key for efficient database operations.
It’s worth noting that while surrogate keys offer various advantages, there are cases where natural keys (based on meaningful attributes) might be more appropriate, especially when the data itself carries important semantic meaning. The choice between surrogate and natural keys depends on the specific requirements of the database schema and the overall data model.
53. If I have a dataframe called student where I have Name, email, department and activity date columns. email column has some duplicate how to remove duplicate name but want to keep the latest records using window function?
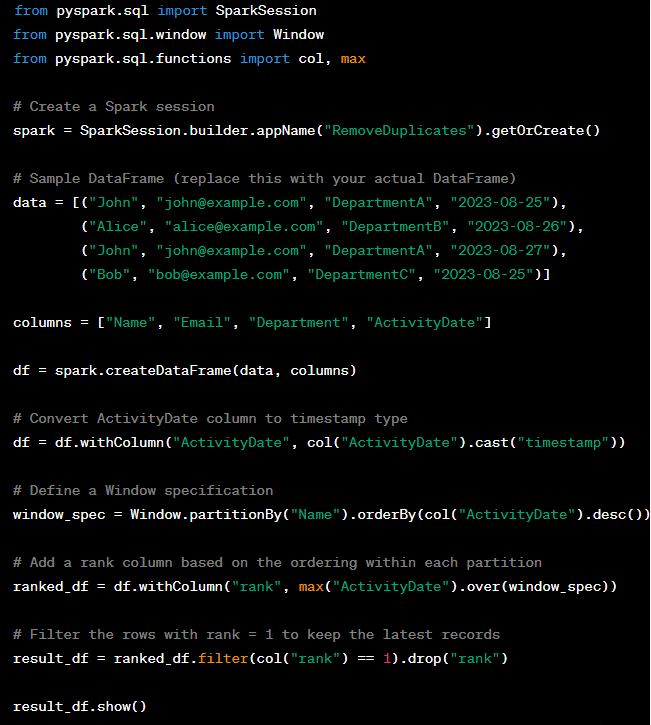
In this code, a window specification is defined partitioned by the “Name” column and ordered by the “ActivityDate” in descending order. The max("ActivityDate").over(window_spec) calculates the maximum activity date within each partition (each name). Then, we filter the rows where the rank is equal to 1, which corresponds to the latest records within each partition.
54. What is Delta Table Versioning ? give an example.
Delta table versioning in Databricks is a feature of Delta Lake, an open-source storage layer that brings ACID (Atomicity, Consistency, Isolation, Durability) transactions to Apache Spark and big data workloads. Delta Lake provides the ability to perform time travel operations, which allows users to query data as it existed at a specific point in time. This is enabled by Delta table versioning.
Let’s say you have a Delta table named ‘sales_data‘, and you want to view the state of the table as it was at version 5 or as it was at a specific timestamp:

55. Is there a hard limit on the maximum number of versions you can retrieve data from? How to Configure Retention Policies?
In Delta Lake, there isn’t a hard limit on the maximum number of versions you can retrieve data from. However, practical limits are imposed by storage costs, performance considerations, and retention policies.
Factors Influencing Version Retention:
- Storage Costs:
- Each version of a Delta table requires storage space. If you retain many versions, the storage cost will increase accordingly.
- Performance:
- As the number of versions increases, certain operations (like querying historical data) might become slower due to the increased size of the transaction log.
- Retention Policies:
- You can configure Delta Lake to automatically clean up old versions based on a defined retention policy. This helps in managing storage costs and maintaining performance.
Configuring Retention Policies:
Delta Lake provides a vacuum command to remove old data files and log files, which helps in managing the number of versions:

This command will retain the last 168 hours (7 days) of versions. You can adjust the retention period based on your requirements.
Leave a Reply