Online Job Posting Analysis
Business Context:
The project seeks to understand the overall demand for labour in the Armenian online job market from the 19,000 job postings from 2004 to 2015 posted on Career Center, an Armenian human resource portal. Through text mining on this data, we will be able to understand the nature of the ever-changing job market, as well as the overall demand for labour in the Armenia economy. The data was originally scraped from a Yahoo! Mailing group.
Business Objectives:
Our main business objectives are to understand the dynamics of the labour market of Armenia using the online job portal post as a proxy. A secondary objective is to implement advanced text analytics as a proof of concept to create additional features such as enhanced search function that can add additional value to the users of the job portal.
So as a Data scientist you need to answer following business questions .
Job Nature and Company Profiles:
What are the types of jobs that are in demand in Armenia? How are the job natures changing over time?
Desired Characteristics and Skill-Sets:
What are the desired characteristics and skill -set of the candidates based on the job description dataset? How these are desired characteristics changing over time?
IT Job Classification:
Build a classifier that can tell us from the job description and company description whether a job is IT or not, so that this column can be automatically populated for new job postings. After doing so, understand what important factors are which drives this classification.
Similarity of Jobs:
Given a job title, find the 5 top jobs that are of a similar nature, based on the job post.
What should be our Text mining goal?
For the IT Job classification business question, you should aim to create supervised learning classification models that are able to classify based on the job text data accurately, is it an IT job.
On the business question of Job Nature and Company Profiles. Unsupervised learning techniques, such as topic modelling and other techniques such as term frequency counting will be applied to the data, including time period segmented dataset. Qualitative assessment will be done on the results to help us understand the job postings.
To understand the desired characteristics and skill -sets demanded by employers in the job ads, unsupervised learning methods such as K-means clustering will be used after appropriate dimension reduction.
For Job Queries business question, we propose exploring the usage of Latent Semantic Model and Matrix Similarity methods for information retrieval. The results will be assessed qualitatively. To return the top 5 most similar job posting, the job text data are vectorised using different models such as word2vec, and doc2vec and similarity scores are obtained using cosine similarity scores, ranked and returned as the answer which is then evaluated individually for relevance.
Data Understanding:
The data was obtained from Kaggle competition. Each row represents a job post. The dataset representation is tabular, but many of the columns are textual/unstructured in nature. Most notably, the columns job Description, Job Requirement, Required Qual, ApplicationP and AboutC are textual. The column job post is an amalgamation of these various textual columns.
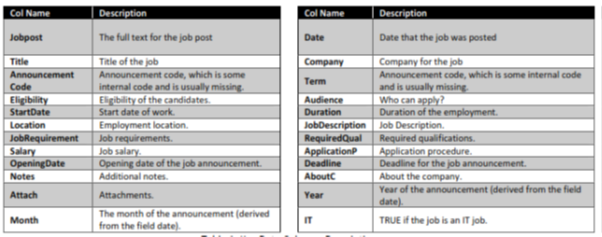
Also provided sample job posting (attached with data set)

Let’s develop a machine learning model for further analysis.