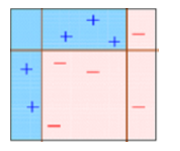
Logistic regression to predict absenteeism- approach
Business Problem:
In today environment there is a high competitiveness which increase pressure on employee. High competitiveness leads unachievable goals, which cause an employee health issues, and health issue will lead absenteeism of employee.
With a given dataset an organisation is trying to predict employee absenteeism.
What is absenteeism in the business context?
Absence from work during normal working hours, resulting in temporary incapacity to execute regular working activity.
Purpose Of Model:
Explore whether a person presenting certain characteristics is expected to be away from work at some points in time or not.
Dataset:
I have downloaded a data set from kaggle called ‘Absenteeism_data.csv’ which contain following information.
- Reason_1 – A Type of Reason to be absent.
- Reason_2 – A Type of Reason to be absent.
- Reason_3 – A Type of Reason to be absent.
- Reason_4 – A Type of Reason to be absent.
- Month Value – Month in which employee has been absent.
- Day of the Week – Days
- Transportation Expense – Expense in dollar
- Distance to Work – Distance of workplace in Km
- Age – Age of employee
- Daily Work Load Average – Average amount of time spent working per day shown in minutes.
- Body Mass Index – Body Mass index of employee.
- Education – Education category(1 – high school education, 2 – Graduate, 3 – Post graduate, 4 – A Master or Doctor )
- Children – No of children an employee has
- Pet – Whether employee has pet or not?
- Absenteeism Time in Hours – How many hours an employee has been absent.
Following are the main action we will take in this project.
- Build the model in python
- Save the result in Mysql.
- Visualise the end result in Tableau
Python for model building:
We are going to take following steps to predict absenteeism:
Load the data
Import the ‘Absenteeism_data.csv’ with the help of pandas
Identify dependent Variable i.e. identify the Y:
We have to be categories and we must find a way to say if someone is ‘being absent too much’ or not. what we’ve decided to do is to take the median of the dataset as a cut-off line in this way the dataset will be balanced (there will be roughly equal number of 0s and 1s for the logistic regression) as balancing is a great problem for ML, this will work great for us alternatively, if we had more data, we could have found other ways to deal with the issue for instance, we could have assigned some arbitrary value as a cut-off line, instead of the median.
Note that what line does is to assign 1 to anyone who has been absent 4 hours or more (more than 3 hours) that is the equivalent of taking half a day off initial code from the lecture targets = np.where(data_preprocessed[‘Absenteeism Time in Hours’] > 3, 1, 0)
Choose Algorithm to develop model:
As our Y (dependent variable) is 1 or o i.e. absent or not absent so we are going to use Logistic regression for our analysis.
Select Input for the regression:
We have to select our all x variables i.e. all independent variable which we will use for regression analysis.
Data Pre-processing:
Remove or treat missing value
In our case there is no missing value so we don’t have to worry about missing value. Yes, there are some columns who is not adding any value in our analysis such as ID which is unique in every case so we will remove it.
Remove Outliers
In our case there are no outliers so we don’t have to worry. But in general if you have outlier you can take log of your x variable to remove outliers.
Standardize the data
standardization is one of the most common pre-processing tools since data of different magnitude (scale) can be biased towards high values, we want all inputs to be of similar magnitude this is a peculiarity of machine learning in general – most (but not all) algorithms do badly with unscaled data. A very useful module we can use is Standard Scaler. It has much more capabilities than the straightforward ‘pre-processing’ method. We will create a variable that will contain the scaling information for this particular dataset.
Here’s the full documentation:
http://scikitlearn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html
Choose the column to scales
In this section we need to choose that variable which need to transform or scale.in our case we need to scale [‘Reason_1’, ‘Reason_2’, ‘Reason_3’, ‘Reason_4′,’Education’, pet and ‘children’], because these are the columns which contain categorical data but in numerical form so we need to transform them.
What about the other column?
‘Month Value’, ‘Day of the Week’, ‘Transportation Expense’, ‘Distance to Work’, ‘Age’, ‘Daily Work Load Average’, ‘Body Mass Index’ . These are the numerical value and their data type is int. so we do not have to transform them but will keep in our analysis.
Note:-
You can ask why we are doing analysis manually column wise?
Because it is always good to analyse data feature wise it gives us a confidence for our model and we can easily interpret our model analysis.
Split Data into train and test
Divide our data into train and test and build the model on train data set.
Apply Algorithm
As per our scenario we are going to use logistic regression in our case. Following steps will take place
Train the model
First we will divide the data into train and test. We will build our model on train data set.
Test the model
When we successfully developed our model then we need to test with a new data set which is testing data sets.
Find the intercepts and coefficient
Find out the beta values and coefficient from model.
Interpreting the coefficients
Find out which feature is adding more values in predictions of Y.
Save the model
Need to save the model which we have prepared so far. To do that we need to pickle the model.
Two executable file will save in your python directory one ‘model’ and the other is ‘scaler’
To save your .Ipnyb file in form of executable, save the same as .py file.
Check Model performance on totally new data set with same features.
Now we have a totally new data set which has same feature as per previous data set but contain different values.
Note – To do that your executable file ‘model’, scaler’ and ‘.py’ file should be in same folder.
Mysql for Data store
Save the prediction in data base (Mysql)
It is always good to save data and prediction on centralised data base. So create a data base in mysql and create a table with all field available in your predicted data frame i.e ‘df_new_obs’
Import ‘pymysql’ library to make connection between ipynb notebook and mysql.
Setup the connection with user name and password and insert the predicted output values. In the data base.
Tableau for Data visualization
Connect the data base with Tableau and visualize the result
As we know tableau is a strong tool to visualise the data. So in our case we will connect our database with tableau and visualise our result and present to the business.
To connect tableau with my sql we need to take following steps.
- Open the tableau desktop application.
- Click on connect data source as mysql.
- Put your data base address, username and password.
- Select the data base.
- Drag the table and visualize your data.