One of the global banks would like to understand what factors driving credit card spend are. The bank want use these insights to calculate credit limit. In order to solve the problem, the bank conducted survey of 5000 customers and collected data.
The objective of this case study is to understand what’s driving the total spend (Primary Card + Secondary card). Given the factors, predict credit limit for the new applicants.
Data Availability:
Data for the case are available in xlsx format.
The data have been provided for 5000 customers.
Detailed data dictionary has been provided
for understanding the data
in the data.
Data is encoded
in the numerical format
to reduce the size of the
data however some of the
variables are categorical. You
can find the details in the data
dictionary
Let’s develop a machine learning model for further analysis.
Decision tree is very simple yet a powerful
algorithm for classification and regression.
As name suggest it has tree like structure. It is a non-parametric technique. A
decision tree typically starts with a single node, which branches into possible
outcomes. Each of those outcomes leads to additional nodes, which branch off
into other possibilities. This gives it a treelike shape.
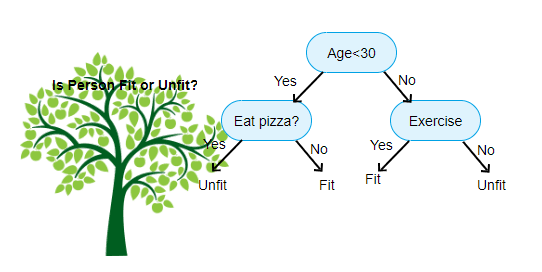
For example of a decision tree can be explained using below binary tree. Let’s suppose you want to predict whether a person is fit by their given information like age, eating habit, and physical activity, etc. The decision nodes here are questions like ‘What’s the age?’, ‘Does he exercise?’, ‘Does he eat a lot of pizzas’? And the leaves, which are outcomes like either ‘fit’, or ‘unfit’. In this case this was a binary classification problem (yes or no type problem).
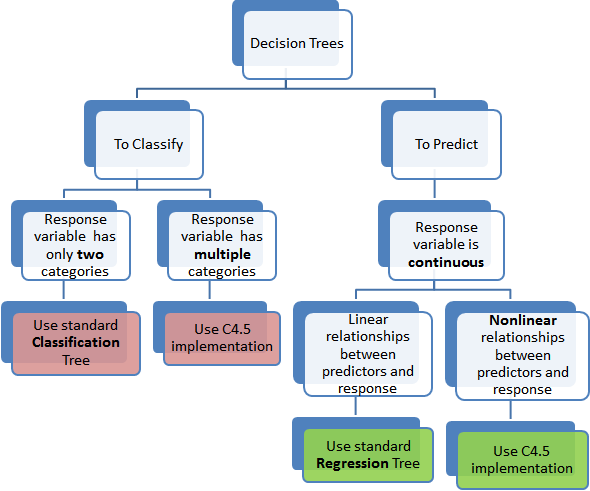
There are two main types of Decision Trees:
Classification trees (Yes/No types)
What we’ve seen above is an example of classification tree, where the outcome was a variable like ‘fit’ or ‘unfit’. Here the decision variable is categorical.
Regression trees (Continuous data types)
Here the decision or the outcome variable is Continuous, e.g. a number like 123.
Image source google.com
The top-most item, in this example, “Age < 30 ?” is called the root. It’s where everything starts from. Branches are what we call each line. A leaf is everything that isn’t the root or a branch.
A general algorithm for a decision tree can be described as follows:
Pick
the best attribute/feature. The best attribute is one which best splits or
separates the data.
Ask
the relevant question.
Follow
the answer path.
Go
to step 1 until you arrive to the answer.
Terms
used with Decision Trees:
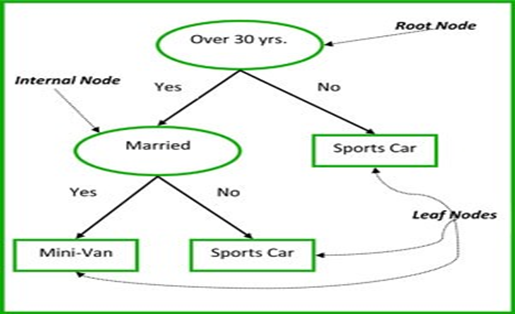
Root
Node – It represents entire population or sample and this
further gets divided into two or more similar sets.
Splitting
– Process
to divide a node into two or more sub nodes.
Decision Node – A
sub node is divided further sub node, called decision node.
Leaf/Terminal Node –
Node which do not split further called leaf node.
Pruning –
When we remove sub-nodes of a decision node, this process is called pruning.
Branch/ Sub-tree –
A sub-section of entire tree is called branch or subtree.
Parent and child node –
A node, which is divided into sub-nodes is called parent node of sub-nodes
whereas sub-nodes are the child of parent node.
Let’s understand above terms with the below image
Image Source google.com
Types of Decision Trees
Categorical Variable decision tree – Decision Tree which has categorical target variable then it called as categorical variable.
Continuous Variable Decision Tree – Decision Tree which has continuous target variable then it is called as Continuous Variable Decision Tree.
Advantages of Decision Tree
Easy to understand – Algorithm is very easy to understand even for people from non-analytical background. A person without statistical knowledge can interpret them.
Useful in data exploration – It is the fastest algorithm to identify most significant variables and relation between variables. It help us to identify those variables which has better power to predict target variable.
Decision tree do not required more effort from user side for data preparation.
This algorithm is not affected by outliers or missing value to an extent, so it required less data cleaning effort as compare to other model.
This model can handle both numerical and categorical variables.
The number of hyper-parameters to be tuned is almost null.
Disadvantages of Decision Tree
Over Fitting – It is the most common problem in decision tree. This issue has resolved by setting constraints on model parameters and pruning. Over fitting is an phenomena where your model create a complex tree that do not generalize the data very well.
Small variations in the data can
result completely different tree which mean it unstable the model. This problem
is called variance, which need to lower by method like bagging and boosting.
If some class is dominate in your
model then decision tree learner can create a biased tree. So it is recommended
to balance the data set prior to fitting with the decision tree.
Calculations can become complex
when there are many class label.
Decision Tree Flowchart
Image Source google.com
How does a tree decide where to split?
In decision tree making splits effect the accuracy of model. The decision criteria are different for classification and regression trees. Decision tree splits the nodes on all available variables and then selects the split which results in most homogeneous sub-nodes.
The algorithm
selection is also based on type of target variables. The four most commonly
used algorithms in decision tree are:
CHAID – Chi-Square Interaction Detector
CART – Classification and regression trees.
Let’s discuss both methods in detail
CHAID – Chi-Square Interaction Detector
It is an algorithm to find out the statistical significance between the differences between sub-nodes and parent node. It works with categorical target variable such as “yes” or “no”.
Algorithm follows following steps:
Iterate all available x variables.
Check if the variable is numeric
If the variable is numeric make it categorical by decile and percentile.
Figure out all possible cuts.
For each possible cut it will do Chi-Square test and store the P value
Choose that cut which give least p value.
Cut the data using that variable and that cut which gives least P value.
CART – Classification and regression trees
There are basically two subtypes for this algorithm.
Gini index:
It says, if we select two items from a population at random then they must be of same class and probability for this is 1 if population is pure. It works with categorical target variable “Success” or “Failure”.
Gini = 1-P^2 – (1-p)^2 , Here p is the probability
Gain = Gini of parents leaf – weighted average of Gini of the nodes (Weights are proportional to population of each child node)
Steps to Calculate Gini for a split
Iterate all available x variables.
Check if the variable is numeric
If the variable is numeric make it categorical by decile and percentile.
Figure out all possible cuts.
Calculate gain for each split
Choose that cut which gives the highest cut.
Cut the data using that variable and that cut which gives maximum gain
Entropy Tree:
To understand entropy tree we need to first understand what entropy is?
Entropy – Entropy is basically measures the level of impurity in a group of examples. If the sample is completely homogeneous, then the entropy is zero and if the sample is an equally divided (50% — 50%), it has entropy of one.
Entropy = -p log2 p — q log2q
Here p and q is the probability of success and failure respectively in that node. Entropy is also used with categorical target variable. It chooses the split which has lowest entropy compared to parent node and other splits. The lesser the entropy, the better it is.
Gain = Entropy of parents leaf – weighted average of entropy of the nodes (Weights are proportional to population of each child node)
Steps to Calculate Entropy for a split
Iterate all available x variables.
Check if the variable is numeric
If the variable is numeric make it categorical by decile and percentile.
Figure out all possible cuts.
Calculate gain for each split
Choose that cut which gives the highest cut.
Cut the data using that variable and that cut which gives maximum gain.
Decision Tree Regression
As we have discussed above with the help of decision tree we can also solve the regression problem. So let’s see what the steps are.
Following steps are involved in algorithm.
Iterate all available x variables.
Check if the variable is numeric
If the variable is numeric make it categorical by decile and percentile.
Figure out all possible cuts.
For each cuts calculate MSE
Choose that cut and that variable which gives the minimum MSE.
Cut the data using that variable and that cut which gives minimum MSE.
Stopping Criteria of Decision Tree
Pure
Node – If tree find a pure node, that particular leaf will stop growing.
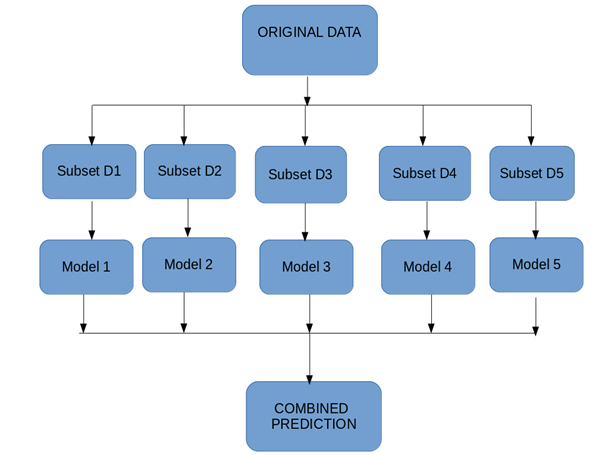
Bootstrap Aggregation (or Bagging for short), is a simple and very powerful ensemble method. Bootstrap method refers to random sampling with replacement. Here with replacement means a sample can be repetitive. Bagging allows model or algorithm to get understand about various biases and variance.
To create bagging model, first we create multiple random samples so that each new random sample will act as another (almost) independent dataset drawn from original distribution. Then, we can fit a weak learner for each of these samples and finally aggregate their outputs and obtain an ensemble model with less variance from its components.
Let’s understand it with an eg.as we can see in below figure where each sample population has different pieces and none of them are identical. This would then affect the overall mean, standard deviation and other descriptive metrics of a data set. It develops more robust models.
How bagging works
How Bagging Works?
You generate multiple samples from your training set using next scheme: you take randomly an element from training set and then return it back. So, some of elements of training set will present multiple times in generated sample and some will be absent. These samples should have the same size as the train set.
You train you learner on each generated sample.
When you apply the algorithm you just average predictions of learners in case of regression or make the voting in case of classification.
Applying bagging often help to deal with overfitting by reducing prediction variance.
Bagging
Algorithms:
Take M bootstrap samples (with replacement)
Train M different classifiers on these bootstrap samples
For a new query, let all classifiers predict and take an average(or majority vote)
If the classifiers make independent errors, then their ensembles can improve performance.
Boosting:
Boosting is an ensemble modeling technique
which converts weak learner to strong learners.
Let’s understand it with an example.
Let’s suppose you want to identify an email is a SPAM or NOT SPAM. To do that
you need to take some criteria as follows.
Email has only one image file, It’s a SPAM
Email has only link, It’s a SPAM
Email body consist of sentence like “You won a prize money of $ xxxx”, It’s a SPAM
Email from our official domain “datasciencelovers.com”, Not a SPAM
Email from known source, Not a SPAM
As we can see above there are multiple rules to identify an email is a spam or not. But if we will talk about individual rules they are not as powerful as multiple rules. There these individual rules is a weak learner.
To convert weak learner to strong learner, we’ll combine the prediction of each weak learner using methods like: • Using average/ weighted average • Considering prediction has higher vote
For example: Above, we have defined 5 weak learners. Out of these 5, 3 are voted as ‘SPAM’ and 2 are voted as ‘Not a SPAM’. In this case, by default, we’ll consider an email as SPAM because we have higher (3) vote for ‘SPAM’
Boosting Algorithm:
The base learner takes all the distributions and assigns equal weight or attention to each observation.
If there is any prediction error caused by first base learning algorithm, then we pay higher attention to observations having prediction error. Then, we apply the next base learning algorithm.
Iterate Step 2 till the limit of base learning algorithm is reached or higher accuracy is achieved.
Finally, it combines the outputs from weak learner and creates a strong learner which eventually improves the prediction power of the model.
Types of Boosting Algorithm:
AdaBoost (Adaptive Boosting)
Gradient Tree Boosting
XGBoost
AdaBoost(Adaptive Boosting)
Adaboost was the first successful and very popular boosting algorithm which developed for the purpose of binary classification. AdaBoost technique which combines multiple “weak classifiers” into a single “strong classifier”.
Initialise the dataset and assign equal weight to each of the data point.
Provide this as input to the model and identify the wrongly classified data points
Increase the weight of the wrongly classified data points.
if (got required results) Go to step 5 else Go to step 2
End
Let’s understand the concept with following example.
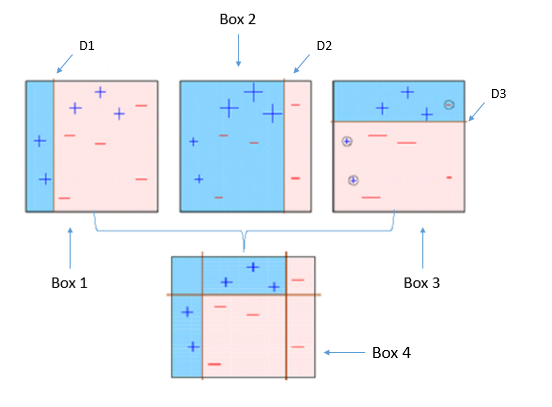
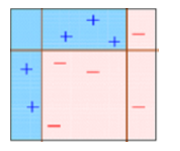
BOX – 1: In box 1 we have assigned equal weight to each data points and applied a decision stump to classify them as + (plus) or – (minus). The decision stump (D1) has generated vertical line at left side to classify the data points. As we can see in the box vertical line has incorrectly predicted three + (plus) as – (minus). In this case, we will assign higher weights to these three + (plus) and apply another decision stump. As you can see in below image.
Decision stump – 1
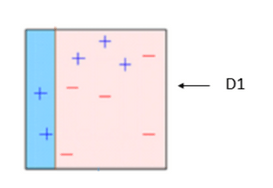
BOX – 2: Now in box 2 size of three incorrectly predicted + (plus) is bigger as compared to rest of the data points. In this case, the second decision stump (D2) will try to predict them correctly. Now, a vertical line (D2) at right side of this box has classified three mis-classified + (plus) correctly. But in this process, it has caused mis-classification errors again. This time with three -(minus). So we will assign higher weight to three – (minus) and apply another decision stump. As you can see in below image.
Decision stump -2
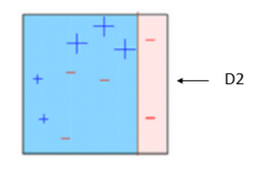
BOX – 3: In box 3 there are three – (minus) has been given higher weights. A decision stump (D3) is applied to predict these mis-classified observation correctly. This time a horizontal line is generated to classify + (plus) and – (minus) based on higher weight of mis-classified observation.
Decision stump – 3
BOX – 4: in box 4 we will combine D1, D2 and D3 to form a strong prediction having complex rule as compared to individual weak learner. As we can see this algorithm has classified these observation quite well as compared to any of individual weak learner.
If ‘SAMME.R’ then use the SAMME.R real boosting algorithm. base estimator must support calculation of class probabilities. If ‘SAMME’ then use the SAMME discrete boosting algorithm.